import pandas as pd
print(pd.__version__)2.2.3Averages are easy for an LLM, right?
A while back, I did a few blog posts on some challenges in properly computing statistics from bike share share transaction data such as the mean and 95th percentile of the number of bikes rented by day of week and hour (or any other time bin) of day.
When ChatGPT was launched a few years ago, this was one of the first things I tried and the results were horrifyingly wrong. Sometimes I’ll assign a similar problem in my classes using either cycle share or airline flight data. For example, I’ll ask students to compute the average number of departing flights from DTW by day of week. Several used some LLM and confidently reported that there were less than 10 flights per day on most days of the week out of DTW. Umm…
I fully expected LLMs to improve and figured now was a good time to see how a few of them might do on this type of problem.
We’ll use the trip.csv datafile from the Pronto Cycleshare Dataset. Let’s explore the file a bit.
import pandas as pd
print(pd.__version__)2.2.3trip = pd.read_csv('data/trip.csv', parse_dates = ['starttime', 'stoptime'])trip.head()| trip_id | starttime | stoptime | bikeid | tripduration | from_station_name | to_station_name | from_station_id | to_station_id | usertype | gender | birthyear | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 431 | 2014-10-13 10:31:00 | 2014-10-13 10:48:00 | SEA00298 | 985.935 | 2nd Ave & Spring St | Occidental Park / Occidental Ave S & S Washing... | CBD-06 | PS-04 | Member | Male | 1960.0 |
| 1 | 432 | 2014-10-13 10:32:00 | 2014-10-13 10:48:00 | SEA00195 | 926.375 | 2nd Ave & Spring St | Occidental Park / Occidental Ave S & S Washing... | CBD-06 | PS-04 | Member | Male | 1970.0 |
| 2 | 433 | 2014-10-13 10:33:00 | 2014-10-13 10:48:00 | SEA00486 | 883.831 | 2nd Ave & Spring St | Occidental Park / Occidental Ave S & S Washing... | CBD-06 | PS-04 | Member | Female | 1988.0 |
| 3 | 434 | 2014-10-13 10:34:00 | 2014-10-13 10:48:00 | SEA00333 | 865.937 | 2nd Ave & Spring St | Occidental Park / Occidental Ave S & S Washing... | CBD-06 | PS-04 | Member | Female | 1977.0 |
| 4 | 435 | 2014-10-13 10:34:00 | 2014-10-13 10:49:00 | SEA00202 | 923.923 | 2nd Ave & Spring St | Occidental Park / Occidental Ave S & S Washing... | CBD-06 | PS-04 | Member | Male | 1971.0 |
I’m going to rename a few columns to match the column names I told Claude were in the file.
trip = trip.rename(mapper = {'starttime': 'start_rental',
'stoptime': 'stop_rental',
'from_station_name': 'from_station',
'to_station_name': 'to_station'}, axis = 1)
trip.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 286857 entries, 0 to 286856
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 trip_id 286857 non-null int64
1 start_rental 286857 non-null datetime64[ns]
2 stop_rental 286857 non-null datetime64[ns]
3 bikeid 286857 non-null object
4 tripduration 286857 non-null float64
5 from_station 286857 non-null object
6 to_station 286857 non-null object
7 from_station_id 286857 non-null object
8 to_station_id 286857 non-null object
9 usertype 286857 non-null object
10 gender 181557 non-null object
11 birthyear 181553 non-null float64
dtypes: datetime64[ns](2), float64(2), int64(1), object(7)
memory usage: 26.3+ MBThe dataframe is pretty big. Let’s create a smaller version to speed up testing.
trip_small = trip.sample(n = 50000)
trip_small.to_csv('data/bike_trips.csv', index=False)Ok, let’s give Claude a whirl.
I thought I’d work up to the most complex computation by starting easy.
You have a csv file named bike_trips.csv. Each row is a bike rental from a bike share system. The fields start_rental and stop_rental are datetime values specifying when the bike is rented and returned. The fields from_station and to_station are strings indicating the bike rental stations that the bike was rented from and returned to. Using Python with pandas, generate the code to compute the total number of rentals from each station.
It responded with the following.
I’ll help you write Python code to analyze the bike rental data and count rentals by station.
import pandas as pd
# Read the CSV file
df = pd.read_csv('bike_trips.csv')
# Count rentals from each station
station_rentals = df['from_station'].value_counts()
# Convert to a DataFrame for better formatting
rental_summary = pd.DataFrame({
'station': station_rentals.index,
'total_rentals': station_rentals.values
})
# Sort by number of rentals in descending order
rental_summary = rental_summary.sort_values('total_rentals', ascending=False)
# Reset index for cleaner display
rental_summary = rental_summary.reset_index(drop=True)
# Display the results
print("\nTotal Rentals by Station:")
print(rental_summary.to_string(index=False))This code will:
Would you like me to modify the analysis in any way? For example, I could:
Nicely done. The explanation and suggestions for future analysis are defintely reasonable. There are a few issues with the code but that’s mostly easy stuff like fixing the path to the data file. Let’s test it.
import pandas as pd
# Read the CSV file
## MY FIX: modified the path
df = pd.read_csv('data/bike_trips.csv')
# Count rentals from each station
station_rentals = df['from_station'].value_counts()
# Convert to a DataFrame for better formatting
rental_summary = pd.DataFrame({
'station': station_rentals.index,
'total_rentals': station_rentals.values
})
# Sort by number of rentals in descending order
rental_summary = rental_summary.sort_values('total_rentals', ascending=False)
# Reset index for cleaner display
rental_summary = rental_summary.reset_index(drop=True)
# Display the results
print("\nTotal Rentals by Station:")
print(rental_summary.to_string(index=False))
Total Rentals by Station:
station total_rentals
Pier 69 / Alaskan Way & Clay St 2276
E Pine St & 16th Ave 2052
3rd Ave & Broad St 1915
2nd Ave & Pine St 1823
Westlake Ave & 6th Ave 1711
E Harrison St & Broadway Ave E 1629
Cal Anderson Park / 11th Ave & Pine St 1607
2nd Ave & Vine St 1498
REI / Yale Ave N & John St 1480
Key Arena / 1st Ave N & Harrison St 1326
PATH / 9th Ave & Westlake Ave 1315
15th Ave E & E Thomas St 1302
Summit Ave & E Denny Way 1187
Dexter Ave N & Aloha St 1184
Summit Ave E & E Republican St 1150
12th Ave & E Mercer St 1110
Seattle Aquarium / Alaskan Way S & Elliott Bay Trail 1086
Pine St & 9th Ave 1077
2nd Ave & Blanchard St 1041
E Blaine St & Fairview Ave E 1000
Occidental Park / Occidental Ave S & S Washington St 983
Republican St & Westlake Ave N 976
Lake Union Park / Valley St & Boren Ave N 964
1st Ave & Marion St 954
7th Ave & Union St 950
2nd Ave & Spring St 947
Harvard Ave & E Pine St 942
9th Ave N & Mercer St 928
Bellevue Ave & E Pine St 916
6th Ave & Blanchard St 865
Dexter Ave & Denny Way 817
Seattle University / E Columbia St & 12th Ave 752
Eastlake Ave E & E Allison St 681
City Hall / 4th Ave & James St 667
Burke-Gilman Trail / NE Blakeley St & 24th Ave NE 664
King Street Station Plaza / 2nd Ave Extension S & S Jackson St 661
Fred Hutchinson Cancer Research Center / Fairview Ave N & Ward St 646
12th Ave & E Denny Way 644
12th Ave & NE Campus Pkwy 601
Frye Art Museum / Terry Ave & Columbia St 566
15th Ave NE & NE 40th St 489
6th Ave S & S King St 480
Union St & 4th Ave 475
UW Engineering Library / E Stevens Way NE & Jefferson Rd 438
NE 47th St & 12th Ave NE 393
Burke Museum / E Stevens Way NE & Memorial Way NE 392
Terry Ave & Stewart St 361
UW Intramural Activities Building 303
Children's Hospital / Sandpoint Way NE & 40th Ave NE 278
NE 42nd St & University Way NE 271
UW Magnuson Health Sciences Center Rotunda / Columbia Rd & San Juan Rd 238
Broadway and E Denny Way 224
NE Pacific St/UW Medical Center 171
Mercer St & 9th Ave N 165
12th Ave & E Yesler Way 153
UW McCarty Hall / Whitman Ct 124
Thomas St & 5th Ave N 123
Pier 66 / Alaskan Way & Bell St 27
8D OPS 02 2Works correctly.
Great. Now using Python and pandas, compute the average length of time in hours that bikes are rented.
It responded with the following code. Again, there were a few easily fixable issues:
parse_dates = parameter to do the datetime conversion on the file read, but no harm.import pandas as pd
## MY FIX: added necessary import
import matplotlib.pyplot as plt
# Read the CSV file
## MY FIX: modified the path
df = pd.read_csv('data/bike_trips.csv')
# Convert datetime strings to datetime objects
df['start_rental'] = pd.to_datetime(df['start_rental'])
df['stop_rental'] = pd.to_datetime(df['stop_rental'])
# Calculate duration in hours for each rental
df['rental_duration'] = (df['stop_rental'] - df['start_rental']).dt.total_seconds() / 3600
# Calculate average duration
average_duration = df['rental_duration'].mean()
# Calculate additional statistics
duration_stats = {
'average_hours': average_duration,
'median_hours': df['rental_duration'].median(),
'min_hours': df['rental_duration'].min(),
'max_hours': df['rental_duration'].max(),
'std_hours': df['rental_duration'].std()
}
# Print results
print("\nRental Duration Statistics (in hours):")
for stat, value in duration_stats.items():
print(f"{stat.replace('_', ' ').title()}: {value:.2f}")
# Create a histogram of rental durations for rentals under 24 hours
short_rentals = df[df['rental_duration'] <= 24]
plt.figure(figsize=(10, 6))
plt.hist(short_rentals['rental_duration'], bins=48, edgecolor='black')
plt.title('Distribution of Rental Durations (≤ 24 hours)')
plt.xlabel('Duration (hours)')
plt.ylabel('Number of Rentals')
plt.grid(True, alpha=0.3)
plt.show()
Rental Duration Statistics (in hours):
Average Hours: 0.32
Median Hours: 0.17
Min Hours: -0.28
Max Hours: 7.98
Std Hours: 0.56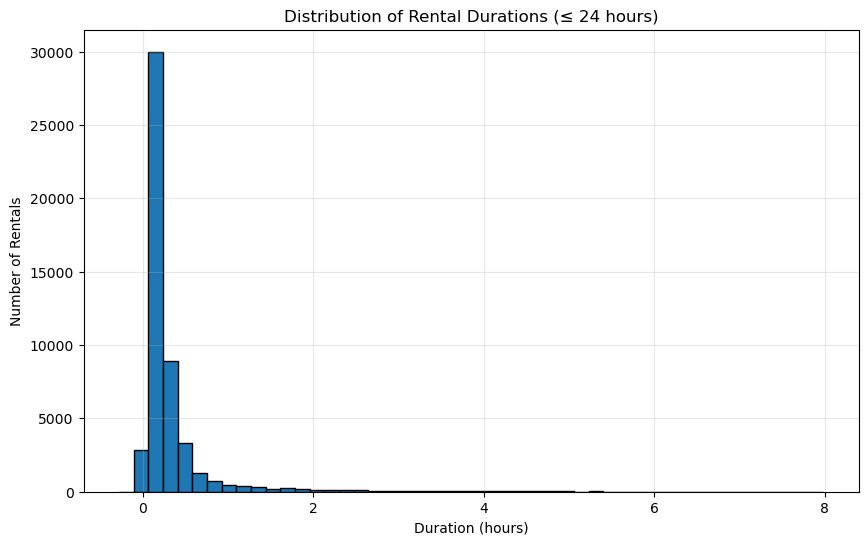
Let’s confirm that the negative minimum is correct. Nice touch with the histogram.
trip_small[trip_small['stop_rental'] < trip_small['start_rental']]| trip_id | start_rental | stop_rental | bikeid | tripduration | from_station | to_station | from_station_id | to_station_id | usertype | gender | birthyear | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 57832 | 8660 | 2014-11-02 01:29:00 | 2014-11-02 01:12:00 | SEA00384 | 2571.017 | Pine St & 9th Ave | Westlake Ave & 6th Ave | SLU-16 | SLU-15 | Short-Term Pass Holder | NaN | NaN |
Great. Nice job, Claude.
Great. Now using Python and pandas, compute the average number of bike rentals by day of week.
I’ll help you analyze the rental patterns by day of week.
import pandas as pd
# Read the CSV file
df = pd.read_csv('bike_trips.csv')
# Convert start_rental to datetime
df['start_rental'] = pd.to_datetime(df['start_rental'])
# Extract day of week (0 = Monday, 6 = Sunday)
df['day_of_week'] = df['start_rental'].dt.dayofweek
# Create day name column for better readability
df['day_name'] = df['start_rental'].dt.day_name()
# Calculate average rentals by day of week
daily_rentals = df.groupby('day_name')['start_rental'].count().reset_index()
daily_rentals.columns = ['day_of_week', 'total_rentals']
# Calculate the number of unique dates for each day of week
unique_days = df.groupby('day_name')['start_rental'].dt.date.nunique().reset_index()
unique_days.columns = ['day_of_week', 'number_of_days']
# Merge and calculate average
daily_averages = pd.merge(daily_rentals, unique_days, on='day_of_week')
daily_averages['average_rentals'] = daily_averages['total_rentals'] / daily_averages['number_of_days']
# Sort by day of week (Monday first)
day_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
daily_averages['day_of_week'] = pd.Categorical(daily_averages['day_of_week'], categories=day_order, ordered=True)
daily_averages = daily_averages.sort_values('day_of_week')
# Round averages to 1 decimal place
daily_averages['average_rentals'] = daily_averages['average_rentals'].round(1)
# Display results
print("\nAverage Daily Rentals by Day of Week:")
print(daily_averages[['day_of_week', 'average_rentals']].to_string(index=False))
# Create a bar plotPython
plt.figure(figsize=(10, 6))
plt.bar(daily_averages['day_of_week'], daily_averages['average_rentals'])
plt.title('Average Number of Bike Rentals by Day of Week')
plt.xlabel('Day of Week')
plt.ylabel('Average Number of Rentals')
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()This code will:
I’ve included:
Would you like me to modify the analysis? For example, I could: - Break down the daily patterns by station - Add hour-of-day analysis within each day - Compare weekday vs weekend patterns - Add seasonal trends by day of week
Let’s try out the code.
import pandas as pd
## MY FIX: added necessary import
import matplotlib.pyplot as plt
# Read the CSV file
## MY FIX: modified the path
df = pd.read_csv('data/bike_trips.csv')
# Convert start_rental to datetime
df['start_rental'] = pd.to_datetime(df['start_rental'])
# Extract day of week (0 = Monday, 6 = Sunday)
df['day_of_week'] = df['start_rental'].dt.dayofweek
# Create day name column for better readability
df['day_name'] = df['start_rental'].dt.day_name()
# Calculate average rentals by day of week
daily_rentals = df.groupby('day_name')['start_rental'].count().reset_index()
daily_rentals.columns = ['day_of_week', 'total_rentals']
# Calculate the number of unique dates for each day of week
unique_days = df.groupby('day_name')['start_rental'].dt.date.nunique().reset_index()
unique_days.columns = ['day_of_week', 'number_of_days']
# Merge and calculate average
daily_averages = pd.merge(daily_rentals, unique_days, on='day_of_week')
daily_averages['average_rentals'] = daily_averages['total_rentals'] / daily_averages['number_of_days']
# Sort by day of week (Monday first)
day_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
daily_averages['day_of_week'] = pd.Categorical(daily_averages['day_of_week'], categories=day_order, ordered=True)
daily_averages = daily_averages.sort_values('day_of_week')
# Round averages to 1 decimal place
daily_averages['average_rentals'] = daily_averages['average_rentals'].round(1)
# Display results
print("\nAverage Daily Rentals by Day of Week:")
print(daily_averages[['day_of_week', 'average_rentals']].to_string(index=False))
# Create a bar plot
plt.figure(figsize=(10, 6))
plt.bar(daily_averages['day_of_week'], daily_averages['average_rentals'])
plt.title('Average Number of Bike Rentals by Day of Week')
plt.xlabel('Day of Week')
plt.ylabel('Average Number of Rentals')
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) Cell In[9], line 24 21 daily_rentals.columns = ['day_of_week', 'total_rentals'] 23 # Calculate the number of unique dates for each day of week ---> 24 unique_days = df.groupby('day_name')['start_rental'].dt.date.nunique().reset_index() 25 unique_days.columns = ['day_of_week', 'number_of_days'] 27 # Merge and calculate average File ~/anaconda3/envs/or310/lib/python3.10/site-packages/pandas/core/groupby/groupby.py:1363, in GroupBy.__getattr__(self, attr) 1360 if attr in self.obj: 1361 return self[attr] -> 1363 raise AttributeError( 1364 f"'{type(self).__name__}' object has no attribute '{attr}'" 1365 ) AttributeError: 'SeriesGroupBy' object has no attribute 'dt'
Well, we have a problem. Reading through the code, Claude definitely has the right idea (partially). He first creates a dataframe with the counts of the total number of rides by day of week.
# Calculate average rentals by day of week
daily_rentals = df.groupby('day_name')['start_rental'].count().reset_index()
daily_rentals.columns = ['day_of_week', 'total_rentals']daily_rentals| day_of_week | total_rentals | |
|---|---|---|
| 0 | Friday | 7403 |
| 1 | Monday | 7480 |
| 2 | Saturday | 6848 |
| 3 | Sunday | 5706 |
| 4 | Thursday | 7659 |
| 5 | Tuesday | 7451 |
| 6 | Wednesday | 7453 |
Now Claude attempts to figure out how many of each weekday appear in the range of dates represented in the dataframe.
# Calculate the number of unique dates for each day of week
unique_days = df.groupby('day_name')['start_rental'].dt.date.nunique().reset_index()--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) Cell In[12], line 2 1 # Calculate the number of unique dates for each day of week ----> 2 unique_days = df.groupby('day_name')['start_rental'].dt.date.nunique().reset_index() File ~/anaconda3/envs/or310/lib/python3.10/site-packages/pandas/core/groupby/groupby.py:1363, in GroupBy.__getattr__(self, attr) 1360 if attr in self.obj: 1361 return self[attr] -> 1363 raise AttributeError( 1364 f"'{type(self).__name__}' object has no attribute '{attr}'" 1365 ) AttributeError: 'SeriesGroupBy' object has no attribute 'dt'
While the dt accessor is usable with a Series or Dataframe object, it’s not usable with a SeriesGroupBy object. Here’s how we can do this while still using the same approach as Claude.
unique_dates_df = pd.DataFrame(df['start_rental'].dt.date.unique(), columns = ['date'])
unique_dates_df['date'] = pd.to_datetime(unique_dates_df['date'])
unique_dates_df['day_of_week'] = unique_dates_df['date'].dt.dayofweek
unique_dates_df['day_name'] = unique_dates_df['date'].dt.day_name()
unique_days = unique_dates_df.groupby('day_name')['date'].size().reset_index()
unique_days.columns = ['day_of_week', 'number_of_days']unique_days| day_of_week | number_of_days | |
|---|---|---|
| 0 | Friday | 98 |
| 1 | Monday | 99 |
| 2 | Saturday | 98 |
| 3 | Sunday | 98 |
| 4 | Thursday | 98 |
| 5 | Tuesday | 99 |
| 6 | Wednesday | 99 |
Now, the rest of the code should work (hopefully).
# Merge and calculate average
daily_averages = pd.merge(daily_rentals, unique_days, on='day_of_week')
daily_averages['average_rentals'] = daily_averages['total_rentals'] / daily_averages['number_of_days']
# Sort by day of week (Monday first)
day_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
daily_averages['day_of_week'] = pd.Categorical(daily_averages['day_of_week'], categories=day_order, ordered=True)
daily_averages = daily_averages.sort_values('day_of_week')
# Round averages to 1 decimal place
daily_averages['average_rentals'] = daily_averages['average_rentals'].round(1)
# Display results
print("\nAverage Daily Rentals by Day of Week:")
print(daily_averages[['day_of_week', 'average_rentals']].to_string(index=False))
# Create a bar plot
plt.figure(figsize=(10, 6))
plt.bar(daily_averages['day_of_week'], daily_averages['average_rentals'])
plt.title('Average Number of Bike Rentals by Day of Week')
plt.xlabel('Day of Week')
plt.ylabel('Average Number of Rentals')
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
Average Daily Rentals by Day of Week:
day_of_week average_rentals
Monday 75.6
Tuesday 75.3
Wednesday 75.3
Thursday 78.2
Friday 75.5
Saturday 69.9
Sunday 58.2
Well, only one major error. I think a pandas novice might have a tough time getting this code working.
But, there’s a more subtle issue here. This approach works fine for computing means under the assumption that we have at least one rental on every date in the range spanned by the dataset (more on this shortly). It’s not going to work if we ask for something like a percentile. In the case of means, we can easily do sums and counts if we don’t have to worry about the case of a date having zero rentals. If we are also interested in such statistics at the station level, then we are likely going to get dates with zero rentals. You can’t ignore these zero periods when computing ride volume statistics. If you do, you will overestimate the statistic (because the 0’s aren’t being included).
Great. Now using Python and pandas, compute the average number of bike rentals by day of week and hour of day.
I’ll help you analyze the rental patterns by both day of week and hour of day.
I moved the code below
This code creates a comprehensive analysis of rental patterns by day and hour:
The heatmap visualization makes it easy to: - Identify rush hour patterns - Compare weekday vs weekend patterns - Spot peak usage times - See the daily cycle of rentals
Would you like me to modify the analysis? I could: - Add seasonal patterns to see how these patterns change throughout the year - Break down patterns by station - Add weather data correlation if available - Create separate visualizations for weekdays vs weekends - Calculate additional statistics about peak vs off-peak usage
Just looking through the code, we’re going to have the same error we say about regarding using the dt accessor on a SeriesGroupBy object. Let’s explore the code a bit. I’ll do it in pieces.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Read the CSV file
## MY FIX: modified the path
df = pd.read_csv('data/bike_trips.csv')
# Convert start_rental to datetime
df['start_rental'] = pd.to_datetime(df['start_rental'])
# Extract day of week and hour
df['day_of_week'] = df['start_rental'].dt.day_name()
df['hour'] = df['start_rental'].dt.hourdf.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50000 entries, 0 to 49999
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 trip_id 50000 non-null int64
1 start_rental 50000 non-null datetime64[ns]
2 stop_rental 50000 non-null object
3 bikeid 50000 non-null object
4 tripduration 50000 non-null float64
5 from_station 50000 non-null object
6 to_station 50000 non-null object
7 from_station_id 50000 non-null object
8 to_station_id 50000 non-null object
9 usertype 50000 non-null object
10 gender 31726 non-null object
11 birthyear 31726 non-null float64
12 day_of_week 50000 non-null object
13 hour 50000 non-null int32
dtypes: datetime64[ns](1), float64(2), int32(1), int64(1), object(9)
memory usage: 5.1+ MBSo far, so good.
# Count rentals by day and hour
rentals_by_day_hour = df.groupby(['day_of_week', 'hour']).size().reset_index()
rentals_by_day_hour.columns = ['day_of_week', 'hour', 'count']rentals_by_day_hour| day_of_week | hour | count | |
|---|---|---|---|
| 0 | Friday | 0 | 38 |
| 1 | Friday | 1 | 22 |
| 2 | Friday | 2 | 19 |
| 3 | Friday | 3 | 13 |
| 4 | Friday | 4 | 18 |
| ... | ... | ... | ... |
| 163 | Wednesday | 19 | 355 |
| 164 | Wednesday | 20 | 260 |
| 165 | Wednesday | 21 | 202 |
| 166 | Wednesday | 22 | 127 |
| 167 | Wednesday | 23 | 62 |
168 rows × 3 columns
Ok, here comes the anticipated problems.
# Calculate unique days for each day of week
unique_days = df.groupby('day_of_week')['start_rental'].dt.date.nunique()--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) Cell In[20], line 2 1 # Calculate unique days for each day of week ----> 2 unique_days = df.groupby('day_of_week')['start_rental'].dt.date.nunique() File ~/anaconda3/envs/or310/lib/python3.10/site-packages/pandas/core/groupby/groupby.py:1363, in GroupBy.__getattr__(self, attr) 1360 if attr in self.obj: 1361 return self[attr] -> 1363 raise AttributeError( 1364 f"'{type(self).__name__}' object has no attribute '{attr}'" 1365 ) AttributeError: 'SeriesGroupBy' object has no attribute 'dt'
Yep, same error. Let’s adapt the code we wrote to do what Claude is tryng to do.
unique_dates_df = pd.DataFrame(df['start_rental'].dt.date.unique(), columns = ['date'])
unique_dates_df['date'] = pd.to_datetime(unique_dates_df['date'])
unique_dates_df['day_of_week'] = unique_dates_df['date'].dt.dayofweek
unique_dates_df['day_name'] = unique_dates_df['date'].dt.day_name()
unique_days = unique_dates_df.groupby('day_name')['date'].size()
unique_days.columns = ['day_of_week', 'number_of_days']unique_daysday_name
Friday 98
Monday 99
Saturday 98
Sunday 98
Thursday 98
Tuesday 99
Wednesday 99
Name: date, dtype: int64Okay, here’s Claude’s final step in computing the average number of bike rentals by day of week and hour of day.
# Calculate averages
rentals_by_day_hour['average_rentals'] = rentals_by_day_hour.apply(
lambda x: x['count'] / unique_days[x['day_of_week']],
axis=1
)rentals_by_day_hour| day_of_week | hour | count | average_rentals | |
|---|---|---|---|---|
| 0 | Friday | 0 | 38 | 0.387755 |
| 1 | Friday | 1 | 22 | 0.224490 |
| 2 | Friday | 2 | 19 | 0.193878 |
| 3 | Friday | 3 | 13 | 0.132653 |
| 4 | Friday | 4 | 18 | 0.183673 |
| ... | ... | ... | ... | ... |
| 163 | Wednesday | 19 | 355 | 3.585859 |
| 164 | Wednesday | 20 | 260 | 2.626263 |
| 165 | Wednesday | 21 | 202 | 2.040404 |
| 166 | Wednesday | 22 | 127 | 1.282828 |
| 167 | Wednesday | 23 | 62 | 0.626263 |
168 rows × 4 columns
# Pivot the data for heatmap
heatmap_data = rentals_by_day_hour.pivot(
index='day_of_week',
columns='hour',
values='average_rentals'
)
# Sort days in correct order
day_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
heatmap_data = heatmap_data.reindex(day_order)
# Create heatmap
plt.figure(figsize=(15, 7))
sns.heatmap(
heatmap_data,
cmap='YlOrRd',
cbar_kws={'label': 'Average Number of Rentals'},
fmt='.1f',
annot=True
)
plt.title('Average Bike Rentals by Day of Week and Hour')
plt.xlabel('Hour of Day')
plt.ylabel('Day of Week')
plt.tight_layout()
plt.show()
# Print summary statistics
print("\nPeak Usage Times:")
# Find top 5 busiest day-hour combinations
peak_times = rentals_by_day_hour.nlargest(5, 'average_rentals')
for _, row in peak_times.iterrows():
print(f"{row['day_of_week']} at {row['hour']:02d}:00 - {row['average_rentals']:.1f} average rentals")
# Calculate overall hourly patterns
hourly_avg = rentals_by_day_hour.groupby('hour')['average_rentals'].mean()
print("\nBusiest Hours (averaged across all days):")
for hour in hourly_avg.nlargest(3).index:
print(f"{hour:02d}:00 - {hourly_avg[hour]:.1f} average rentals")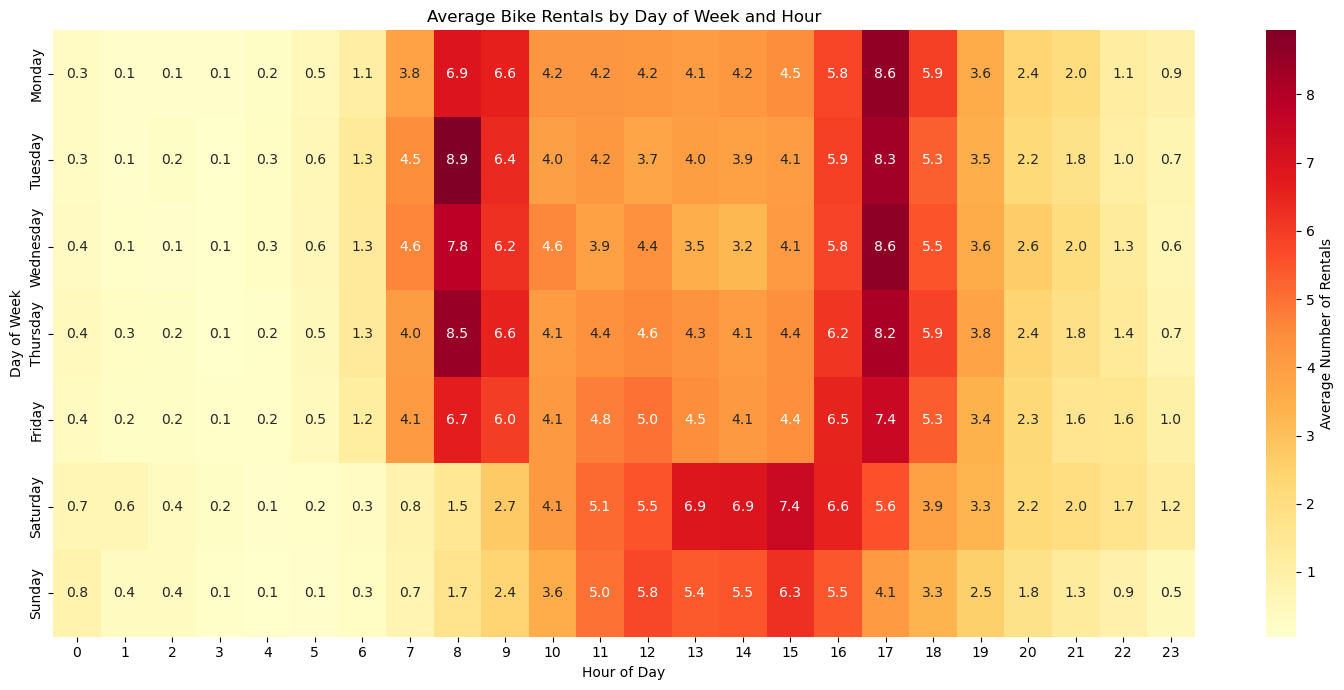
Peak Usage Times:
Tuesday at 08:00 - 8.9 average rentals
Wednesday at 17:00 - 8.6 average rentals
Monday at 17:00 - 8.6 average rentals
Thursday at 08:00 - 8.5 average rentals
Tuesday at 17:00 - 8.3 average rentals
Busiest Hours (averaged across all days):
17:00 - 7.3 average rentals
16:00 - 6.0 average rentals
08:00 - 6.0 average rentalsWell, that seems impressive. Again, it only works with means as long as there are no dates with zero volume.
Now let’s add computing the 95th percentile of rental volume.
Using Python and pandas, can you compute the mean and 95th percentile of the number of bikes rented by day of week?
I moved the code below
This code:
Would you like me to add any additional statistics or modify the analysis in any way?
Let’s work our way through the code.
import pandas as pd
import numpy as np
# Read the CSV file
## MY FIX: modified the path
df = pd.read_csv('data/bike_trips.csv')
# Convert start_rental to datetime
df['start_rental'] = pd.to_datetime(df['start_rental'])
# Extract date and day of week
df['date'] = df['start_rental'].dt.date
df['day_of_week'] = df['start_rental'].dt.day_name()
# Get daily counts
daily_counts = df.groupby(['date', 'day_of_week']).size().reset_index(name='count')daily_counts| date | day_of_week | count | |
|---|---|---|---|
| 0 | 2014-10-13 | Monday | 146 |
| 1 | 2014-10-14 | Tuesday | 158 |
| 2 | 2014-10-15 | Wednesday | 111 |
| 3 | 2014-10-16 | Thursday | 150 |
| 4 | 2014-10-17 | Friday | 92 |
| ... | ... | ... | ... |
| 684 | 2016-08-27 | Saturday | 65 |
| 685 | 2016-08-28 | Sunday | 80 |
| 686 | 2016-08-29 | Monday | 64 |
| 687 | 2016-08-30 | Tuesday | 59 |
| 688 | 2016-08-31 | Wednesday | 54 |
689 rows × 3 columns
Well this is already much better than earlier versions of LLMs did on this problem. Claude computed the number of rentals by date, which was not done when just computing the mean number of rentals. To do percentiles, we need the full dataset of rides by date, whereas for a mean we could get by with a summation of rides by day of week and a count of the number of days of the week in the date range of the dataset.
# Calculate statistics by day of week
stats = daily_counts.groupby('day_of_week').agg({
'count': [
('mean', 'mean'),
('95th_percentile', lambda x: np.percentile(x, 95))
]
}).round(1)
# Flatten column names and reset index
stats.columns = ['mean', '95th_percentile']
stats = stats.reset_index()
# Sort days in correct order
day_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
stats['day_of_week'] = pd.Categorical(stats['day_of_week'], categories=day_order, ordered=True)
stats = stats.sort_values('day_of_week')
# Display results
print("\nBike Rental Statistics by Day of Week:")
print("(All values rounded to 1 decimal place)")
print("\nDay of Week | Mean Rentals | 95th Percentile")
print("-" * 45)
for _, row in stats.iterrows():
print(f"{row['day_of_week']:<10} | {row['mean']:>11.1f} | {row['95th_percentile']:>15.1f}")
# Calculate overall summary statistics
print("\nSummary Statistics:")
print(f"Overall Mean Daily Rentals: {stats['mean'].mean():.1f}")
print(f"Highest Mean Daily Rentals: {stats['mean'].max():.1f} ({stats.loc[stats['mean'].idxmax(), 'day_of_week']})")
print(f"Highest 95th Percentile: {stats['95th_percentile'].max():.1f} ({stats.loc[stats['95th_percentile'].idxmax(), 'day_of_week']})")
Bike Rental Statistics by Day of Week:
(All values rounded to 1 decimal place)
Day of Week | Mean Rentals | 95th Percentile
---------------------------------------------
Monday | 75.6 | 135.1
Tuesday | 75.3 | 123.0
Wednesday | 75.3 | 127.2
Thursday | 78.2 | 133.4
Friday | 75.5 | 123.7
Saturday | 69.9 | 144.0
Sunday | 58.2 | 103.2
Summary Statistics:
Overall Mean Daily Rentals: 72.6
Highest Mean Daily Rentals: 78.2 (Thursday)
Highest 95th Percentile: 144.0 (Saturday)Impressive. Again, this approach assumes we have at least one rental on each date in the range of dates spanned by our dataset. It’s a totally reasonable assumption for the entire bike share system. But, what happens if we want to do this analysis at the station level and not all stations have rentals on every date? Will Claude handle this correctly?
Using Python and pandas, can you compute the mean and 95th percentile of the number of bikes rented by day of week for station CH-06?
My reaction to response 6
Let’s jump right to the generated code.
import pandas as pd
import numpy as np
# Read the CSV file
## MY FIX: modified the path
df = pd.read_csv('data/bike_trips.csv')
# Convert start_rental to datetime
df['start_rental'] = pd.to_datetime(df['start_rental'])
# Filter for station CH-06 (12th Ave & E Denny Way)
## MY FIX: Using the station name instead of the ID because that's the field I told Claude about
station_df = df[df['from_station'] == '12th Ave & E Denny Way']
# Extract date and day of week
station_df['date'] = station_df['start_rental'].dt.date
station_df['day_of_week'] = station_df['start_rental'].dt.day_name()
# Get daily counts
daily_counts = station_df.groupby(['date', 'day_of_week']).size().reset_index(name='count')/tmp/ipykernel_22505/1411289504.py:16: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
station_df['date'] = station_df['start_rental'].dt.date
/tmp/ipykernel_22505/1411289504.py:17: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
station_df['day_of_week'] = station_df['start_rental'].dt.day_name()daily_counts| date | day_of_week | count | |
|---|---|---|---|
| 0 | 2014-10-13 | Monday | 1 |
| 1 | 2014-10-14 | Tuesday | 3 |
| 2 | 2014-10-15 | Wednesday | 3 |
| 3 | 2014-10-17 | Friday | 1 |
| 4 | 2014-10-19 | Sunday | 2 |
| ... | ... | ... | ... |
| 399 | 2016-08-20 | Saturday | 1 |
| 400 | 2016-08-24 | Wednesday | 1 |
| 401 | 2016-08-25 | Thursday | 1 |
| 402 | 2016-08-26 | Friday | 1 |
| 403 | 2016-08-27 | Saturday | 1 |
404 rows × 3 columns
Uh oh. There are only 404 dates on which there were one or more rentals. On the other \(689-404\) days, there were zero rentals. We need these 285 zero values to compute the correct mean and 95th percentile of the number of rentals by day of week at this station. Ignoring the zero values will inflate the statistics.
# Calculate statistics by day of week
stats = daily_counts.groupby('day_of_week').agg({
'count': [
('mean', 'mean'),
('95th_percentile', lambda x: np.percentile(x, 95))
]
}).round(1)
# Flatten column names and reset index
stats.columns = ['mean', '95th_percentile']
stats = stats.reset_index()
# Sort days in correct order
day_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
stats['day_of_week'] = pd.Categorical(stats['day_of_week'], categories=day_order, ordered=True)
stats = stats.sort_values('day_of_week')
# Display results
print("\nBike Rental Statistics for Station CH-06 by Day of Week:")
print("(All values rounded to 1 decimal place)")
print("\nDay of Week | Mean Rentals | 95th Percentile")
print("-" * 45)
for _, row in stats.iterrows():
print(f"{row['day_of_week']:<10} | {row['mean']:>11.1f} | {row['95th_percentile']:>15.1f}")
# Calculate overall summary statistics
print("\nSummary Statistics for Station CH-06:")
print(f"Overall Mean Daily Rentals: {stats['mean'].mean():.1f}")
print(f"Highest Mean Daily Rentals: {stats['mean'].max():.1f} ({stats.loc[stats['mean'].idxmax(), 'day_of_week']})")
print(f"Highest 95th Percentile: {stats['95th_percentile'].max():.1f} ({stats.loc[stats['95th_percentile'].idxmax(), 'day_of_week']})")
# Add total number of rentals info
total_rentals = len(station_df)
total_days = len(daily_counts['date'].unique())
print(f"\nTotal number of rentals from CH-06: {total_rentals}")
print(f"Number of days in dataset: {total_days}")
Bike Rental Statistics for Station CH-06 by Day of Week:
(All values rounded to 1 decimal place)
Day of Week | Mean Rentals | 95th Percentile
---------------------------------------------
Monday | 1.7 | 3.0
Tuesday | 1.6 | 3.0
Wednesday | 1.5 | 3.0
Thursday | 1.7 | 3.0
Friday | 1.6 | 3.0
Saturday | 1.5 | 3.0
Sunday | 1.5 | 2.0
Summary Statistics for Station CH-06:
Overall Mean Daily Rentals: 1.6
Highest Mean Daily Rentals: 1.7 (Monday)
Highest 95th Percentile: 3.0 (Monday)
Total number of rentals from CH-06: 644
Number of days in dataset: 404On the surface looks reasonable, but these values are all inflated due to ignoring the zero days.
Let’s compute the correct statistics.
We’ll start by getting the date range of our dataset.
df['tripdate'] = df['start_rental'].dt.date
min_date = df['tripdate'].min()
max_date = df['tripdate'].max()
num_days = max_date - min_date + pd.Timedelta(1, 'd')
print(f'{num_days.days} days - {min_date} to {max_date}')689 days - 2014-10-13 to 2016-08-31Now we’ll create a dataframe containing all the dates.
dates_seeded = pd.DataFrame(pd.date_range(min_date, max_date), columns = ['tripdate'])
dates_seeded['day_of_week'] = dates_seeded['tripdate'].dt.day_name()
dates_seeded| tripdate | day_of_week | |
|---|---|---|
| 0 | 2014-10-13 | Monday |
| 1 | 2014-10-14 | Tuesday |
| 2 | 2014-10-15 | Wednesday |
| 3 | 2014-10-16 | Thursday |
| 4 | 2014-10-17 | Friday |
| ... | ... | ... |
| 684 | 2016-08-27 | Saturday |
| 685 | 2016-08-28 | Sunday |
| 686 | 2016-08-29 | Monday |
| 687 | 2016-08-30 | Tuesday |
| 688 | 2016-08-31 | Wednesday |
689 rows × 2 columns
dates_seeded.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 689 entries, 0 to 688
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 tripdate 689 non-null datetime64[ns]
1 day_of_week 689 non-null object
dtypes: datetime64[ns](1), object(1)
memory usage: 10.9+ KBNow do a left join with daily_counts and dates_seeded.
daily_counts['tripdate'] = pd.to_datetime(daily_counts['date'])
trips_by_date_merged = pd.merge(dates_seeded, daily_counts, how='left',
left_on='tripdate', right_on='tripdate', sort=True, suffixes=(None, '_y'))
trips_by_date_merged| tripdate | day_of_week | date | day_of_week_y | count | |
|---|---|---|---|---|---|
| 0 | 2014-10-13 | Monday | 2014-10-13 | Monday | 1.0 |
| 1 | 2014-10-14 | Tuesday | 2014-10-14 | Tuesday | 3.0 |
| 2 | 2014-10-15 | Wednesday | 2014-10-15 | Wednesday | 3.0 |
| 3 | 2014-10-16 | Thursday | NaN | NaN | NaN |
| 4 | 2014-10-17 | Friday | 2014-10-17 | Friday | 1.0 |
| ... | ... | ... | ... | ... | ... |
| 684 | 2016-08-27 | Saturday | 2016-08-27 | Saturday | 1.0 |
| 685 | 2016-08-28 | Sunday | NaN | NaN | NaN |
| 686 | 2016-08-29 | Monday | NaN | NaN | NaN |
| 687 | 2016-08-30 | Tuesday | NaN | NaN | NaN |
| 688 | 2016-08-31 | Wednesday | NaN | NaN | NaN |
689 rows × 5 columns
You can see the NaN values for the missing dates. We need to update the counts to 0.
# Fill in any missing values with 0.
trips_by_date_merged['count'] = trips_by_date_merged['count'].fillna(0)
trips_by_date_merged| tripdate | day_of_week | date | day_of_week_y | count | |
|---|---|---|---|---|---|
| 0 | 2014-10-13 | Monday | 2014-10-13 | Monday | 1.0 |
| 1 | 2014-10-14 | Tuesday | 2014-10-14 | Tuesday | 3.0 |
| 2 | 2014-10-15 | Wednesday | 2014-10-15 | Wednesday | 3.0 |
| 3 | 2014-10-16 | Thursday | NaN | NaN | 0.0 |
| 4 | 2014-10-17 | Friday | 2014-10-17 | Friday | 1.0 |
| ... | ... | ... | ... | ... | ... |
| 684 | 2016-08-27 | Saturday | 2016-08-27 | Saturday | 1.0 |
| 685 | 2016-08-28 | Sunday | NaN | NaN | 0.0 |
| 686 | 2016-08-29 | Monday | NaN | NaN | 0.0 |
| 687 | 2016-08-30 | Tuesday | NaN | NaN | 0.0 |
| 688 | 2016-08-31 | Wednesday | NaN | NaN | 0.0 |
689 rows × 5 columns
Now we can use the rest of Claude’s code (with appropriate dataframe):
# Calculate statistics by day of week
stats = trips_by_date_merged.groupby('day_of_week').agg({
'count': [
('mean', 'mean'),
('95th_percentile', lambda x: np.percentile(x, 95))
]
}).round(1)
# Flatten column names and reset index
stats.columns = ['mean', '95th_percentile']
stats = stats.reset_index()
# Sort days in correct order
day_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
stats['day_of_week'] = pd.Categorical(stats['day_of_week'], categories=day_order, ordered=True)
stats = stats.sort_values('day_of_week')
# Display results
print("\nBike Rental Statistics for Station CH-06 by Day of Week:")
print("(All values rounded to 1 decimal place)")
print("\nDay of Week | Mean Rentals | 95th Percentile")
print("-" * 45)
for _, row in stats.iterrows():
print(f"{row['day_of_week']:<10} | {row['mean']:>11.1f} | {row['95th_percentile']:>15.1f}")
# Calculate overall summary statistics
print("\nSummary Statistics for Station CH-06:")
print(f"Overall Mean Daily Rentals: {stats['mean'].mean():.1f}")
print(f"Highest Mean Daily Rentals: {stats['mean'].max():.1f} ({stats.loc[stats['mean'].idxmax(), 'day_of_week']})")
print(f"Highest 95th Percentile: {stats['95th_percentile'].max():.1f} ({stats.loc[stats['95th_percentile'].idxmax(), 'day_of_week']})")
# Add total number of rentals info
total_rentals = len(station_df)
total_days = len(trips_by_date_merged['tripdate'].unique())
print(f"\nTotal number of rentals from CH-06: {total_rentals}")
print(f"Number of days in dataset: {total_days}")
Bike Rental Statistics for Station CH-06 by Day of Week:
(All values rounded to 1 decimal place)
Day of Week | Mean Rentals | 95th Percentile
---------------------------------------------
Monday | 1.0 | 3.0
Tuesday | 0.9 | 3.0
Wednesday | 1.1 | 3.0
Thursday | 1.2 | 3.0
Friday | 0.9 | 2.1
Saturday | 0.7 | 2.0
Sunday | 0.7 | 2.0
Summary Statistics for Station CH-06:
Overall Mean Daily Rentals: 0.9
Highest Mean Daily Rentals: 1.2 (Thursday)
Highest 95th Percentile: 3.0 (Monday)
Total number of rentals from CH-06: 644
Number of days in dataset: 689Now all the values are lower than the inflated values from Claude’s attempt.
Just for fun, let’s plot the number of trips by date so we can actually see the zero days and see that the station appears to have been open for the entire analysis period. Such a plot would be part of the process of determining the analysis timeframe.
trips_by_date_merged.plot(y='count');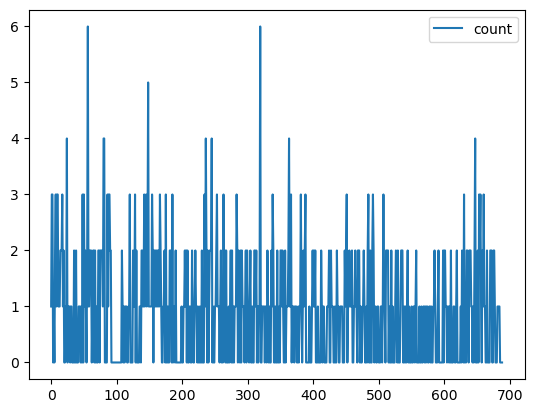
In this particular case, differences in computed stats, while not huge, are certainly present. Taking zero days into account is important in computing temporal statistics such averages and percentiles of number of trips per day.
While there have been improvements, Claude 3.5 Sonnet is not up to the task of correctly computing statistics such as the mean and 95th percentile of rental volume by day of week for cases in which there are dates with no rentals. It takes a naive approach that inflates the statistics in this case. The differences might not be readily apparent to the analyst that does not carefully check the code and output generated by Claude.
In the next part of this series, I’ll see how MS Copilot does on this same problem.
There are additional subtleties involved in analyzing bike share data. See my previous posts for more on this.
@online{isken2025,
author = {Isken, Mark},
title = {Computing Daily Averages from Transaction Data Using {LLMs}
Can Be Tricky - {Part} 1: {Claude}},
date = {2025-02-07},
url = {https://bitsofanalytics.org/posts/llms-cycleshare-part1/daily_averages_cycleshare_part1.html},
langid = {en}
}