import pandas as pdComputing daily averages from transaction data using pandas can be tricky - Part 2
Now let’s add a grouping field
python
pandas
bikeshare
In Part 1 of this post, we discuss the importance of taking into account days with zero activity as well as carefully specifiying the date range for analysis when computing things like the average number of bike trips by day in a bike share system. Obviously, this applies more generally to computing averages number of events per day. We showed an approach to dealing with these complications.
In Part 2 of this post, we’ll extend this to cases in which we might want to group by an additional field (e.g. station_id for the bike share example) and see how this problem is just one part of the general problem of doing occupancy analysis based on transaction data. We’ll see how the hillmaker package can make these types of analyses easier.
trip = pd.read_csv('trip.csv', parse_dates = ['starttime', 'stoptime'])
trip['tripdate'] = trip['starttime'].map(lambda x: x.date())trip.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 286857 entries, 0 to 286856
Data columns (total 13 columns):
trip_id 286857 non-null int64
starttime 286857 non-null datetime64[ns]
stoptime 286857 non-null datetime64[ns]
bikeid 286857 non-null object
tripduration 286857 non-null float64
from_station_name 286857 non-null object
to_station_name 286857 non-null object
from_station_id 286857 non-null object
to_station_id 286857 non-null object
usertype 286857 non-null object
gender 181557 non-null object
birthyear 181553 non-null float64
tripdate 286857 non-null object
dtypes: datetime64[ns](2), float64(2), int64(1), object(8)
memory usage: 28.5+ MBtrip.head()| trip_id | starttime | stoptime | bikeid | tripduration | from_station_name | to_station_name | from_station_id | to_station_id | usertype | gender | birthyear | tripdate | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 431 | 2014-10-13 10:31:00 | 2014-10-13 10:48:00 | SEA00298 | 985.935 | 2nd Ave & Spring St | Occidental Park / Occidental Ave S & S Washing... | CBD-06 | PS-04 | Member | Male | 1960.0 | 2014-10-13 |
| 1 | 432 | 2014-10-13 10:32:00 | 2014-10-13 10:48:00 | SEA00195 | 926.375 | 2nd Ave & Spring St | Occidental Park / Occidental Ave S & S Washing... | CBD-06 | PS-04 | Member | Male | 1970.0 | 2014-10-13 |
| 2 | 433 | 2014-10-13 10:33:00 | 2014-10-13 10:48:00 | SEA00486 | 883.831 | 2nd Ave & Spring St | Occidental Park / Occidental Ave S & S Washing... | CBD-06 | PS-04 | Member | Female | 1988.0 | 2014-10-13 |
| 3 | 434 | 2014-10-13 10:34:00 | 2014-10-13 10:48:00 | SEA00333 | 865.937 | 2nd Ave & Spring St | Occidental Park / Occidental Ave S & S Washing... | CBD-06 | PS-04 | Member | Female | 1977.0 | 2014-10-13 |
| 4 | 435 | 2014-10-13 10:34:00 | 2014-10-13 10:49:00 | SEA00202 | 923.923 | 2nd Ave & Spring St | Occidental Park / Occidental Ave S & S Washing... | CBD-06 | PS-04 | Member | Male | 1971.0 | 2014-10-13 |
What is the average number of bike rentals per day from each station?
Not only do we need to take into account days in which no bikes were rented from each of the stations, we have to decide how we want to handle the fact that not all stations were open for the period of time represented in the trip dataframe.
print("The first trip was at {}.".format(trip.starttime.min()))
print("The last trip was at {}.".format(trip.starttime.max()))The first trip was at 2014-10-13 10:31:00.
The last trip was at 2016-08-31 23:49:00.We can get a sense of the timeframes for when individual stations were open by looking an min and max of the starttime field.
trip.groupby('from_station_id')['starttime'].aggregate(['min', 'max'])| min | max | |
|---|---|---|
| from_station_id | ||
| 8D OPS 02 | 2016-08-12 09:03:00 | 2016-08-12 09:06:00 |
| BT-01 | 2014-10-13 15:39:00 | 2016-08-31 22:13:00 |
| BT-03 | 2014-10-13 12:35:00 | 2016-08-31 17:21:00 |
| BT-04 | 2014-10-13 12:05:00 | 2016-08-31 19:31:00 |
| BT-05 | 2014-10-13 13:08:00 | 2016-08-31 18:21:00 |
| CBD-03 | 2014-10-13 13:30:00 | 2016-08-31 19:36:00 |
| CBD-04 | 2015-07-27 15:52:00 | 2016-08-31 20:44:00 |
| CBD-05 | 2014-10-13 11:52:00 | 2016-08-31 17:26:00 |
| CBD-06 | 2014-10-13 10:31:00 | 2016-08-31 20:32:00 |
| CBD-07 | 2014-10-13 11:49:00 | 2016-08-31 18:23:00 |
| CBD-13 | 2014-10-13 12:58:00 | 2016-08-31 19:58:00 |
| CD-01 | 2015-05-23 08:01:00 | 2016-08-09 18:43:00 |
| CH-01 | 2014-10-13 16:31:00 | 2016-08-31 22:37:00 |
| CH-02 | 2014-10-13 11:54:00 | 2016-08-31 21:59:00 |
| CH-03 | 2014-10-13 17:16:00 | 2016-08-31 20:33:00 |
| CH-05 | 2014-10-13 13:45:00 | 2016-08-31 20:43:00 |
| CH-06 | 2014-10-13 15:33:00 | 2016-08-31 15:44:00 |
| CH-07 | 2014-10-13 14:06:00 | 2016-08-31 19:27:00 |
| CH-08 | 2014-10-13 13:32:00 | 2016-08-31 23:49:00 |
| CH-09 | 2014-10-13 13:01:00 | 2016-08-31 23:34:00 |
| CH-12 | 2014-10-13 17:51:00 | 2016-08-31 18:30:00 |
| CH-15 | 2014-10-13 13:08:00 | 2016-08-31 20:57:00 |
| CH-16 | 2016-03-19 01:06:00 | 2016-08-31 17:38:00 |
| DPD-01 | 2014-10-13 11:59:00 | 2016-08-31 18:57:00 |
| DPD-03 | 2014-10-13 13:43:00 | 2016-08-31 19:32:00 |
| EL-01 | 2014-10-13 15:03:00 | 2016-08-31 19:03:00 |
| EL-03 | 2014-10-13 18:19:00 | 2016-08-31 17:35:00 |
| EL-05 | 2014-10-13 15:05:00 | 2016-08-30 18:23:00 |
| FH-01 | 2014-10-13 12:59:00 | 2016-03-18 17:19:00 |
| FH-04 | 2014-10-13 18:44:00 | 2016-08-31 20:58:00 |
| ... | ... | ... |
| PS-04 | 2014-10-13 11:35:00 | 2016-08-31 18:10:00 |
| PS-05 | 2014-10-13 11:51:00 | 2016-08-31 16:47:00 |
| Pronto shop | 2015-06-02 20:36:00 | 2015-06-02 20:36:00 |
| Pronto shop 2 | 2016-05-17 12:03:00 | 2016-05-17 15:41:00 |
| SLU-01 | 2014-10-13 13:09:00 | 2016-08-31 18:54:00 |
| SLU-02 | 2014-10-13 13:51:00 | 2016-08-31 18:02:00 |
| SLU-04 | 2014-10-13 15:34:00 | 2016-08-31 21:27:00 |
| SLU-07 | 2014-10-13 19:11:00 | 2016-08-31 18:49:00 |
| SLU-15 | 2014-10-13 13:02:00 | 2016-08-31 18:57:00 |
| SLU-16 | 2014-10-13 20:57:00 | 2016-08-31 16:10:00 |
| SLU-17 | 2014-10-13 14:53:00 | 2016-08-31 19:17:00 |
| SLU-18 | 2014-10-13 13:02:00 | 2016-07-02 11:09:00 |
| SLU-19 | 2014-10-13 13:38:00 | 2016-08-31 22:02:00 |
| SLU-20 | 2015-06-12 15:13:00 | 2016-08-31 18:36:00 |
| SLU-21 | 2015-09-19 16:24:00 | 2016-08-30 18:41:00 |
| SLU-22 | 2016-07-03 19:35:00 | 2016-08-31 14:20:00 |
| UD-01 | 2014-10-13 12:02:00 | 2016-08-31 17:32:00 |
| UD-02 | 2014-10-13 12:48:00 | 2016-08-31 08:07:00 |
| UD-04 | 2014-10-13 12:54:00 | 2016-08-31 09:24:00 |
| UD-07 | 2014-10-13 13:20:00 | 2016-08-31 08:48:00 |
| UW-01 | 2014-10-14 16:35:00 | 2015-10-27 17:26:00 |
| UW-02 | 2014-10-13 12:15:00 | 2016-08-31 15:08:00 |
| UW-04 | 2014-10-13 14:49:00 | 2016-08-31 18:43:00 |
| UW-06 | 2014-10-13 14:21:00 | 2016-08-30 15:26:00 |
| UW-07 | 2014-10-13 12:37:00 | 2016-08-30 20:44:00 |
| UW-10 | 2014-10-13 13:04:00 | 2016-08-30 13:50:00 |
| UW-11 | 2015-11-05 16:28:00 | 2016-08-31 21:35:00 |
| WF-01 | 2014-10-13 13:45:00 | 2016-08-31 22:47:00 |
| WF-03 | 2016-08-10 10:36:00 | 2016-08-31 17:52:00 |
| WF-04 | 2014-10-13 12:04:00 | 2016-08-31 22:10:00 |
61 rows × 2 columns
Let’s look at the station.csv file so that we can see the installation and decommision dates.
station = pd.read_csv('station.csv',
parse_dates = ['install_date', 'modification_date', 'decommission_date'])station.head(15)| station_id | name | lat | long | install_date | install_dockcount | modification_date | current_dockcount | decommission_date | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | BT-01 | 3rd Ave & Broad St | 47.618418 | -122.350964 | 2014-10-13 | 18 | NaT | 18 | NaT |
| 1 | BT-03 | 2nd Ave & Vine St | 47.615829 | -122.348564 | 2014-10-13 | 16 | NaT | 16 | NaT |
| 2 | BT-04 | 6th Ave & Blanchard St | 47.616094 | -122.341102 | 2014-10-13 | 16 | NaT | 16 | NaT |
| 3 | BT-05 | 2nd Ave & Blanchard St | 47.613110 | -122.344208 | 2014-10-13 | 14 | NaT | 14 | NaT |
| 4 | CBD-03 | 7th Ave & Union St | 47.610731 | -122.332447 | 2014-10-13 | 20 | NaT | 20 | NaT |
| 5 | CBD-04 | Union St & 4th Ave | 47.609221 | -122.335596 | 2015-07-27 | 18 | NaT | 18 | NaT |
| 6 | CBD-05 | 1st Ave & Marion St | 47.604058 | -122.335800 | 2014-10-13 | 20 | NaT | 20 | NaT |
| 7 | CBD-06 | 2nd Ave & Spring St | 47.605950 | -122.335768 | 2014-10-13 | 20 | 2015-11-09 | 18 | NaT |
| 8 | CBD-07 | City Hall / 4th Ave & James St | 47.603509 | -122.330409 | 2014-10-13 | 20 | NaT | 20 | NaT |
| 9 | CBD-13 | 2nd Ave & Pine St | 47.610185 | -122.339641 | 2014-10-13 | 18 | NaT | 18 | NaT |
| 10 | CD-01 | 12th Ave & E Yesler Way | 47.602103 | -122.316923 | 2015-05-22 | 16 | 2016-08-09 | 0 | 2016-08-09 |
| 11 | CH-01 | Summit Ave & E Denny Way | 47.618633 | -122.325249 | 2014-10-13 | 16 | NaT | 16 | NaT |
| 12 | CH-02 | E Harrison St & Broadway Ave E | 47.622063 | -122.321251 | 2014-10-13 | 18 | 2015-02-24 | 20 | NaT |
| 13 | CH-03 | Summit Ave E & E Republican St | 47.623367 | -122.325279 | 2014-10-13 | 16 | NaT | 16 | NaT |
| 14 | CH-05 | 15th Ave E & E Thomas St | 47.620712 | -122.312805 | 2014-10-13 | 16 | NaT | 16 | NaT |
To simplify things, let’s only consider trips for stations who have not been decommissioned.
# Create a list of stations to consider for the analysis
active_stations = list(station[station.decommission_date.isna()]['station_id'])
# Only keep records for active stations
trip = trip[trip.from_station_id.isin(active_stations)]Now let’s create a DataFrame containing the analysis start and end dates for each active stations. For the start date we’ll use the install_date field and for end date we’ll use the last date in the trip data - 2016-08-31.
# Just grab the rows of active stations
station_dates = station[station.decommission_date.isna()]
# Just grab columns of interest
station_dates = station_dates[['station_id','install_date','decommission_date']]
# Rename the date columns
station_dates.rename(columns={'install_date': 'start_date', 'decommission_date': 'end_date'},
inplace=True)
# Set end date for all stations
station_dates.end_date = pd.datetime(2016, 8, 31)
# Check out the result
station_dates.head(7)| station_id | start_date | end_date | |
|---|---|---|---|
| 0 | BT-01 | 2014-10-13 | 2016-08-31 |
| 1 | BT-03 | 2014-10-13 | 2016-08-31 |
| 2 | BT-04 | 2014-10-13 | 2016-08-31 |
| 3 | BT-05 | 2014-10-13 | 2016-08-31 |
| 4 | CBD-03 | 2014-10-13 | 2016-08-31 |
| 5 | CBD-04 | 2015-07-27 | 2016-08-31 |
| 6 | CBD-05 | 2014-10-13 | 2016-08-31 |
In Part 1 we outlined the basic strategy for computing the average number of daily events when some days might not have any events.
- Create a range of dates based on the start and end date of the time period of interest.
- Create an empty DataFrame using the range of dates as the index. For convenience, add weekday column based on date to facility day of week analysis. Let’s call this new DataFrame the “seeded” DataFrame
- Use groupby on the original trip DataFrame to compute number of trips by date and store result as DataFrame
- Merge the two DataFrames on their indexes (tripdate) but do a “left join”. Pandas
mergefunction is perfect for this. - If there are dates with no trips, they’ll have missing data in the new merged DataFrame. Update the missing values to 0 using the
fillnafunction in pandas. - Now you can compute overall mean number of trips per day. You could also compute means by day of week.
In order to compute the average number of trips per day by station, a few details in the above process have to be generalized.
- In Step 1, the start and end dates can depend on the station.
- In Step 2, we need a DataFrame containing each station and its associated date range.
- In Step 3, we need to group by both station and trip date.
Accounting for zero days and station specific analysis timeframe
Steps 1 and 2: Create an empty DataFrame using stations and associated range of dates as the MultiIndex.
We’ll construct the desired MultiIndex from a list of tuples of station ids and dates. To create the list of tuples we can use a list comprehension to iterate over the rows of the station_dates dataframe and associated date range. Gotta love list comprehensions.
index_tuples = [(row.station_id, d) for index, row in station_dates.iterrows()
for d in pd.date_range(row.start_date, row.end_date)]
print(index_tuples[:5])[('BT-01', Timestamp('2014-10-13 00:00:00', freq='D')), ('BT-01', Timestamp('2014-10-14 00:00:00', freq='D')), ('BT-01', Timestamp('2014-10-15 00:00:00', freq='D')), ('BT-01', Timestamp('2014-10-16 00:00:00', freq='D')), ('BT-01', Timestamp('2014-10-17 00:00:00', freq='D'))]Create the empty DataFrame and add a weekday column for convenience.
trips_by_station_date_seeded = pd.DataFrame(index=pd.MultiIndex.from_tuples(index_tuples))# Add weekday column to new dataframe
trips_by_station_date_seeded['weekday'] = \
trips_by_station_date_seeded.index.get_level_values(1).map(lambda x: x.weekday())
trips_by_station_date_seeded.index.names = ['from_station_id', 'tripdate']
print(trips_by_station_date_seeded.head())
print(trips_by_station_date_seeded.tail()) weekday
from_station_id tripdate
BT-01 2014-10-13 0
2014-10-14 1
2014-10-15 2
2014-10-16 3
2014-10-17 4
weekday
from_station_id tripdate
WF-03 2016-08-27 5
2016-08-28 6
2016-08-29 0
2016-08-30 1
2016-08-31 2Step 3: Use groupby on the original trip DataFrame to compute number of trips by station by date
# Create a Group by object using from_station_id and tripdate
grp_station_date = trip.groupby(['from_station_id', 'tripdate'])
# Compute number of trips by date and check out the result
trips_by_station_date = pd.DataFrame(grp_station_date.size(), columns=['num_trips'])
print(trips_by_station_date.head()) num_trips
from_station_id tripdate
BT-01 2014-10-13 20
2014-10-14 28
2014-10-15 8
2014-10-16 24
2014-10-17 16Step 4: Merge the two DataFrames on their indexes but do a “left join”.
Pandas merge function is perfect for this. The left_index=True, right_index=True are telling pandas to use those respective indexes as the joining columns. Check out the documentation for merge().
# Merge the two dataframes doing a left join (with seeded table on left)
trips_by_station_date_merged = pd.merge(trips_by_station_date_seeded,
trips_by_station_date, how='left',
left_index=True, right_index=True, sort=True)trips_by_station_date_merged[100:125]| weekday | num_trips | ||
|---|---|---|---|
| from_station_id | tripdate | ||
| BT-01 | 2015-01-21 | 2 | 2.0 |
| 2015-01-22 | 3 | 8.0 | |
| 2015-01-23 | 4 | 12.0 | |
| 2015-01-24 | 5 | 28.0 | |
| 2015-01-25 | 6 | 20.0 | |
| 2015-01-26 | 0 | 12.0 | |
| 2015-01-27 | 1 | 12.0 | |
| 2015-01-28 | 2 | 10.0 | |
| 2015-01-29 | 3 | 14.0 | |
| 2015-01-30 | 4 | 10.0 | |
| 2015-01-31 | 5 | 14.0 | |
| 2015-02-01 | 6 | 2.0 | |
| 2015-02-02 | 0 | 2.0 | |
| 2015-02-03 | 1 | 6.0 | |
| 2015-02-04 | 2 | 8.0 | |
| 2015-02-05 | 3 | 2.0 | |
| 2015-02-06 | 4 | NaN | |
| 2015-02-07 | 5 | 14.0 | |
| 2015-02-08 | 6 | 14.0 | |
| 2015-02-09 | 0 | 10.0 | |
| 2015-02-10 | 1 | 8.0 | |
| 2015-02-11 | 2 | 10.0 | |
| 2015-02-12 | 3 | 18.0 | |
| 2015-02-13 | 4 | 30.0 | |
| 2015-02-14 | 5 | 52.0 |
Step 5: Replace missing values with zeroes for those dates with no trips
If there are dates with no trips, they’ll have missing data in the new merged DataFrame. Update the missing values to 0 using the fillna function in pandas. Remember, these are the instances of “zero activity” that would cause biased (high) estimates of the average number of daily trips.
# How many missing values do we have?
trips_by_station_date_merged['num_trips'].isna().sum()3072# Fill in any missing values with 0.
trips_by_station_date_merged['num_trips'] = trips_by_station_date_merged['num_trips'].fillna(0)
trips_by_station_date_merged[100:125]| weekday | num_trips | ||
|---|---|---|---|
| from_station_id | tripdate | ||
| BT-01 | 2015-01-21 | 2 | 2.0 |
| 2015-01-22 | 3 | 8.0 | |
| 2015-01-23 | 4 | 12.0 | |
| 2015-01-24 | 5 | 28.0 | |
| 2015-01-25 | 6 | 20.0 | |
| 2015-01-26 | 0 | 12.0 | |
| 2015-01-27 | 1 | 12.0 | |
| 2015-01-28 | 2 | 10.0 | |
| 2015-01-29 | 3 | 14.0 | |
| 2015-01-30 | 4 | 10.0 | |
| 2015-01-31 | 5 | 14.0 | |
| 2015-02-01 | 6 | 2.0 | |
| 2015-02-02 | 0 | 2.0 | |
| 2015-02-03 | 1 | 6.0 | |
| 2015-02-04 | 2 | 8.0 | |
| 2015-02-05 | 3 | 2.0 | |
| 2015-02-06 | 4 | 0.0 | |
| 2015-02-07 | 5 | 14.0 | |
| 2015-02-08 | 6 | 14.0 | |
| 2015-02-09 | 0 | 10.0 | |
| 2015-02-10 | 1 | 8.0 | |
| 2015-02-11 | 2 | 10.0 | |
| 2015-02-12 | 3 | 18.0 | |
| 2015-02-13 | 4 | 30.0 | |
| 2015-02-14 | 5 | 52.0 |
Step 6: Compute statistics of interest
Now we can safely compute means and other statistics of interest for the num_trips column after grouping by from_station_id. Since we have taken the zero activity days into account, the stations having count values less than 689 are those stations which were installed sometime after 2014-10-13 (the installation date is in the station table).
trips_by_station_date_merged.groupby('from_station_id')['num_trips'].describe()| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| from_station_id | ||||||||
| BT-01 | 689.0 | 15.869376 | 10.729919 | 0.0 | 8.0 | 14.0 | 22.00 | 62.0 |
| BT-03 | 689.0 | 11.854862 | 7.494522 | 0.0 | 6.0 | 10.0 | 16.00 | 52.0 |
| BT-04 | 689.0 | 6.798258 | 4.590017 | 0.0 | 3.0 | 6.0 | 10.00 | 26.0 |
| BT-05 | 689.0 | 9.100145 | 6.731142 | 0.0 | 4.0 | 8.0 | 13.00 | 42.0 |
| CBD-03 | 689.0 | 8.062409 | 7.649699 | 0.0 | 3.0 | 6.0 | 10.00 | 57.0 |
| CBD-04 | 402.0 | 6.699005 | 4.044817 | 0.0 | 4.0 | 7.0 | 9.00 | 22.0 |
| CBD-05 | 689.0 | 8.165457 | 5.902446 | 0.0 | 4.0 | 7.0 | 12.00 | 50.0 |
| CBD-06 | 689.0 | 7.930334 | 6.506778 | 0.0 | 3.0 | 7.0 | 11.00 | 52.0 |
| CBD-07 | 689.0 | 5.271408 | 5.189189 | 0.0 | 2.0 | 4.0 | 8.00 | 72.0 |
| CBD-13 | 689.0 | 14.584906 | 9.699203 | 0.0 | 7.0 | 13.0 | 21.00 | 82.0 |
| CH-01 | 689.0 | 9.822932 | 5.693529 | 0.0 | 6.0 | 9.0 | 12.00 | 38.0 |
| CH-02 | 689.0 | 13.989840 | 7.987720 | 0.0 | 8.0 | 13.0 | 18.00 | 48.0 |
| CH-03 | 689.0 | 9.544267 | 5.981427 | 0.0 | 5.0 | 8.0 | 13.00 | 36.0 |
| CH-05 | 689.0 | 11.146589 | 6.491743 | 0.0 | 7.0 | 10.0 | 15.00 | 40.0 |
| CH-06 | 689.0 | 5.568940 | 3.525442 | 0.0 | 3.0 | 5.0 | 8.00 | 26.0 |
| CH-07 | 689.0 | 16.534107 | 7.045270 | 0.0 | 12.0 | 16.0 | 21.00 | 40.0 |
| CH-08 | 689.0 | 13.741655 | 8.355998 | 0.0 | 8.0 | 12.0 | 19.00 | 68.0 |
| CH-09 | 689.0 | 8.269956 | 5.721211 | 0.0 | 4.0 | 7.0 | 11.00 | 54.0 |
| CH-12 | 689.0 | 8.052250 | 5.954298 | 0.0 | 4.0 | 7.0 | 12.00 | 34.0 |
| CH-15 | 689.0 | 9.175617 | 5.059781 | 0.0 | 6.0 | 8.0 | 12.00 | 34.0 |
| CH-16 | 167.0 | 7.712575 | 3.112551 | 0.0 | 6.0 | 8.0 | 10.00 | 16.0 |
| DPD-01 | 689.0 | 7.490566 | 5.212656 | 0.0 | 4.0 | 7.0 | 10.00 | 32.0 |
| DPD-03 | 689.0 | 2.404935 | 2.601996 | 0.0 | 0.0 | 2.0 | 4.00 | 18.0 |
| EL-01 | 689.0 | 5.195936 | 4.585833 | 0.0 | 2.0 | 4.0 | 7.00 | 29.0 |
| EL-03 | 689.0 | 8.341074 | 5.414082 | 0.0 | 5.0 | 8.0 | 11.00 | 38.0 |
| EL-05 | 689.0 | 5.290276 | 5.603926 | 0.0 | 2.0 | 4.0 | 7.00 | 48.0 |
| FH-04 | 689.0 | 5.917271 | 3.751411 | 0.0 | 3.0 | 6.0 | 8.00 | 22.0 |
| ID-04 | 689.0 | 3.963716 | 3.996745 | 0.0 | 1.0 | 3.0 | 6.00 | 24.0 |
| PS-04 | 689.0 | 8.195936 | 8.135708 | 0.0 | 4.0 | 7.0 | 11.00 | 142.0 |
| PS-05 | 689.0 | 5.613933 | 4.158087 | 0.0 | 3.0 | 5.0 | 8.00 | 30.0 |
| SLU-01 | 689.0 | 12.165457 | 9.145079 | 0.0 | 5.0 | 10.0 | 17.00 | 50.0 |
| SLU-02 | 689.0 | 10.068215 | 5.630042 | 0.0 | 6.0 | 10.0 | 14.00 | 32.0 |
| SLU-04 | 689.0 | 8.233672 | 6.192806 | 0.0 | 4.0 | 7.0 | 12.00 | 48.0 |
| SLU-07 | 689.0 | 10.458636 | 7.894570 | 0.0 | 4.0 | 8.0 | 15.00 | 42.0 |
| SLU-15 | 689.0 | 14.505080 | 8.536365 | 0.0 | 8.0 | 14.0 | 20.00 | 48.0 |
| SLU-16 | 689.0 | 8.795356 | 8.992095 | 0.0 | 3.0 | 6.0 | 12.00 | 51.0 |
| SLU-17 | 689.0 | 8.238026 | 7.888482 | 0.0 | 2.0 | 6.0 | 12.00 | 68.0 |
| SLU-19 | 689.0 | 10.865022 | 6.683941 | 0.0 | 6.0 | 10.0 | 15.00 | 36.0 |
| SLU-20 | 447.0 | 4.774049 | 3.943030 | 0.0 | 2.0 | 4.0 | 7.00 | 22.0 |
| SLU-21 | 352.0 | 2.451705 | 2.590350 | 0.0 | 1.0 | 2.0 | 4.00 | 20.0 |
| SLU-22 | 60.0 | 12.683333 | 6.215049 | 4.0 | 9.0 | 11.0 | 16.25 | 28.0 |
| UD-01 | 689.0 | 5.492017 | 4.780381 | 0.0 | 2.0 | 4.0 | 8.00 | 30.0 |
| UD-02 | 689.0 | 2.081277 | 2.709117 | 0.0 | 0.0 | 1.0 | 3.00 | 16.0 |
| UD-04 | 689.0 | 5.268505 | 4.673858 | 0.0 | 2.0 | 4.0 | 8.00 | 30.0 |
| UD-07 | 689.0 | 3.708273 | 3.380511 | 0.0 | 1.0 | 3.0 | 5.00 | 26.0 |
| UW-02 | 689.0 | 3.001451 | 3.168476 | 0.0 | 1.0 | 2.0 | 4.00 | 22.0 |
| UW-04 | 689.0 | 4.065312 | 3.487949 | 0.0 | 2.0 | 3.0 | 6.00 | 26.0 |
| UW-06 | 689.0 | 3.902758 | 4.051716 | 0.0 | 1.0 | 3.0 | 6.00 | 26.0 |
| UW-07 | 689.0 | 2.682148 | 3.015799 | 0.0 | 0.0 | 2.0 | 4.00 | 24.0 |
| UW-10 | 689.0 | 2.029028 | 2.601827 | 0.0 | 0.0 | 1.0 | 3.00 | 18.0 |
| UW-11 | 308.0 | 3.207792 | 3.306642 | 0.0 | 0.0 | 2.0 | 5.25 | 16.0 |
| WF-01 | 689.0 | 18.946299 | 14.597358 | 0.0 | 7.0 | 16.0 | 28.00 | 110.0 |
| WF-03 | 23.0 | 6.956522 | 3.831428 | 0.0 | 4.0 | 6.0 | 9.50 | 14.0 |
| WF-04 | 689.0 | 9.226415 | 8.179196 | 0.0 | 3.0 | 8.0 | 13.00 | 60.0 |
Can even do by day of week.
trips_by_station_date_merged.groupby(['from_station_id', 'weekday'])['num_trips'].describe()| count | mean | std | min | 25% | 50% | 75% | max | ||
|---|---|---|---|---|---|---|---|---|---|
| from_station_id | weekday | ||||||||
| BT-01 | 0 | 99.0 | 15.282828 | 9.574669 | 2.0 | 8.00 | 13.0 | 20.00 | 56.0 |
| 1 | 99.0 | 13.949495 | 8.374370 | 2.0 | 8.00 | 12.0 | 19.50 | 38.0 | |
| 2 | 99.0 | 13.525253 | 7.661650 | 2.0 | 8.00 | 12.0 | 18.00 | 39.0 | |
| 3 | 98.0 | 15.285714 | 10.632570 | 0.0 | 7.25 | 13.0 | 18.00 | 62.0 | |
| 4 | 98.0 | 17.377551 | 11.544191 | 0.0 | 9.25 | 16.0 | 21.75 | 61.0 | |
| 5 | 98.0 | 20.632653 | 14.058338 | 0.0 | 8.25 | 18.0 | 30.75 | 58.0 | |
| 6 | 98.0 | 15.081633 | 10.674832 | 0.0 | 6.00 | 14.5 | 22.00 | 46.0 | |
| BT-03 | 0 | 99.0 | 11.676768 | 6.948540 | 1.0 | 7.00 | 11.0 | 16.00 | 38.0 |
| 1 | 99.0 | 12.151515 | 6.153419 | 2.0 | 8.00 | 11.0 | 16.00 | 30.0 | |
| 2 | 99.0 | 12.676768 | 7.296670 | 1.0 | 7.00 | 12.0 | 17.50 | 32.0 | |
| 3 | 98.0 | 12.336735 | 7.303359 | 0.0 | 6.25 | 11.5 | 16.00 | 40.0 | |
| 4 | 98.0 | 12.755102 | 7.065323 | 0.0 | 7.00 | 12.0 | 18.00 | 34.0 | |
| 5 | 98.0 | 10.877551 | 8.820390 | 0.0 | 4.00 | 8.5 | 15.00 | 42.0 | |
| 6 | 98.0 | 10.500000 | 8.474644 | 0.0 | 5.00 | 9.0 | 14.00 | 52.0 | |
| BT-04 | 0 | 99.0 | 7.858586 | 5.076979 | 0.0 | 4.00 | 7.0 | 10.00 | 26.0 |
| 1 | 99.0 | 7.878788 | 4.291122 | 1.0 | 5.00 | 7.0 | 10.00 | 24.0 | |
| 2 | 99.0 | 7.919192 | 4.006823 | 0.0 | 5.00 | 8.0 | 10.00 | 20.0 | |
| 3 | 98.0 | 7.816327 | 4.782586 | 0.0 | 4.00 | 7.0 | 11.00 | 24.0 | |
| 4 | 98.0 | 7.755102 | 4.240359 | 0.0 | 5.00 | 7.0 | 10.00 | 20.0 | |
| 5 | 98.0 | 4.346939 | 3.964019 | 0.0 | 2.00 | 4.0 | 6.00 | 23.0 | |
| 6 | 98.0 | 3.979592 | 3.508398 | 0.0 | 1.00 | 3.0 | 6.00 | 16.0 | |
| BT-05 | 0 | 99.0 | 9.454545 | 6.429004 | 1.0 | 4.50 | 8.0 | 13.50 | 32.0 |
| 1 | 99.0 | 9.030303 | 6.333350 | 1.0 | 4.00 | 8.0 | 13.00 | 28.0 | |
| 2 | 99.0 | 9.040404 | 6.626969 | 0.0 | 4.00 | 7.0 | 12.50 | 34.0 | |
| 3 | 98.0 | 9.540816 | 7.211343 | 0.0 | 4.00 | 8.0 | 14.00 | 30.0 | |
| 4 | 98.0 | 10.255102 | 6.709451 | 0.0 | 5.00 | 9.0 | 14.00 | 42.0 | |
| 5 | 98.0 | 9.000000 | 7.550517 | 0.0 | 3.00 | 8.0 | 13.00 | 42.0 | |
| 6 | 98.0 | 7.377551 | 5.999167 | 0.0 | 3.00 | 7.0 | 10.00 | 28.0 | |
| CBD-03 | 0 | 99.0 | 8.585859 | 8.279567 | 0.0 | 4.00 | 6.0 | 10.00 | 57.0 |
| 1 | 99.0 | 8.393939 | 6.589754 | 0.0 | 4.00 | 6.0 | 12.00 | 34.0 | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| UW-10 | 5 | 98.0 | 2.377551 | 3.131204 | 0.0 | 0.00 | 1.5 | 3.75 | 18.0 |
| 6 | 98.0 | 1.775510 | 3.000105 | 0.0 | 0.00 | 0.0 | 2.00 | 16.0 | |
| UW-11 | 0 | 44.0 | 3.272727 | 3.142830 | 0.0 | 1.00 | 3.0 | 5.00 | 11.0 |
| 1 | 44.0 | 3.181818 | 3.074824 | 0.0 | 0.00 | 2.0 | 6.00 | 10.0 | |
| 2 | 44.0 | 3.431818 | 3.030064 | 0.0 | 0.00 | 3.0 | 6.00 | 11.0 | |
| 3 | 44.0 | 3.772727 | 3.469895 | 0.0 | 1.00 | 2.5 | 6.00 | 16.0 | |
| 4 | 44.0 | 3.681818 | 3.489337 | 0.0 | 0.75 | 3.0 | 6.00 | 13.0 | |
| 5 | 44.0 | 2.636364 | 3.424202 | 0.0 | 0.00 | 1.0 | 3.25 | 12.0 | |
| 6 | 44.0 | 2.477273 | 3.480769 | 0.0 | 0.00 | 1.0 | 3.00 | 15.0 | |
| WF-01 | 0 | 99.0 | 17.212121 | 11.908900 | 0.0 | 7.00 | 16.0 | 26.00 | 56.0 |
| 1 | 99.0 | 16.222222 | 10.312025 | 2.0 | 8.00 | 14.0 | 21.50 | 56.0 | |
| 2 | 99.0 | 15.616162 | 10.238689 | 2.0 | 7.00 | 13.0 | 22.00 | 44.0 | |
| 3 | 98.0 | 18.438776 | 11.849630 | 2.0 | 9.00 | 17.5 | 26.00 | 66.0 | |
| 4 | 98.0 | 17.979592 | 13.641945 | 0.0 | 6.00 | 14.0 | 28.00 | 53.0 | |
| 5 | 98.0 | 24.530612 | 19.283669 | 0.0 | 8.00 | 22.0 | 37.00 | 74.0 | |
| 6 | 98.0 | 22.704082 | 19.682641 | 0.0 | 5.25 | 20.0 | 34.75 | 110.0 | |
| WF-03 | 0 | 3.0 | 4.000000 | 1.000000 | 3.0 | 3.50 | 4.0 | 4.50 | 5.0 |
| 1 | 4.0 | 5.000000 | 4.690416 | 0.0 | 2.25 | 4.5 | 7.25 | 11.0 | |
| 2 | 4.0 | 6.250000 | 2.872281 | 4.0 | 4.00 | 5.5 | 7.75 | 10.0 | |
| 3 | 3.0 | 8.333333 | 4.041452 | 4.0 | 6.50 | 9.0 | 10.50 | 12.0 | |
| 4 | 3.0 | 10.333333 | 3.214550 | 8.0 | 8.50 | 9.0 | 11.50 | 14.0 | |
| 5 | 3.0 | 7.333333 | 5.859465 | 3.0 | 4.00 | 5.0 | 9.50 | 14.0 | |
| 6 | 3.0 | 8.333333 | 3.055050 | 5.0 | 7.00 | 9.0 | 10.00 | 11.0 | |
| WF-04 | 0 | 99.0 | 8.383838 | 6.974746 | 0.0 | 3.00 | 6.0 | 12.00 | 32.0 |
| 1 | 99.0 | 7.525253 | 6.221004 | 0.0 | 3.00 | 6.0 | 11.00 | 32.0 | |
| 2 | 99.0 | 6.888889 | 6.057360 | 0.0 | 2.00 | 6.0 | 10.00 | 29.0 | |
| 3 | 98.0 | 8.163265 | 6.818250 | 0.0 | 4.00 | 6.5 | 12.00 | 36.0 | |
| 4 | 98.0 | 8.765306 | 6.601782 | 0.0 | 4.00 | 7.5 | 11.00 | 29.0 | |
| 5 | 98.0 | 13.326531 | 10.597389 | 0.0 | 4.00 | 12.0 | 19.00 | 48.0 | |
| 6 | 98.0 | 11.581633 | 10.658643 | 0.0 | 2.25 | 9.5 | 18.00 | 60.0 |
378 rows × 8 columns
A similar example using R - airline flights
Here’s how you can do the same thing using R. I’ll use the nycflights13 package and we’ll compute the average number of flights by day of week by carrier.
In order to use R magic within Jupyter notebook cells, you need to:
pip install rpy2The latest version (2.9.4 as of this post) requires the tzlocal module as well.
pip install tzlocalNow you can load the rpy2.ipython module via a magic command.
%load_ext rpy2.ipythonNow just put %%R at top of any cell you want to treat as an R code chunk.
%%R
library(dplyr, quietly = TRUE, warn.conflicts = FALSE, verbose = FALSE)
library(lubridate, quietly = TRUE, warn.conflicts = FALSE, verbose = FALSE)
library(ggplot2, quietly = TRUE, warn.conflicts = FALSE, verbose = FALSE)
library(nycflights13, quietly = TRUE, warn.conflicts = FALSE, verbose = FALSE)Load the NYC Flights data package and add a flight date field.
%%R
flights <- nycflights13::flights
flights$fl_date <- with(flights, ISOdate(year, month, day))Count the number of flights by date by carrier.
%%R
flights_by_date_carrier_1 <- flights %>%
group_by(carrier, fl_date) %>%
summarize(numflights = n())We need to make sure that we have a data frame containing every combination of fl_date and carrier so that the days with zero flights are properly accounted for when computing the average number of flights by day of week. R has a function called expand.grid which is perfect for this. I’ll create two vectors - one containing all the dates and one containing all the carriers. Then expand.grid will create a dataframe with all the combinations of the elements of two vectors.
%%R
dates <- seq(ymd('2013-01-01'),ymd('2013-12-31'),by='days')
carriers <- unique(flights$carrier)
date_carrier <- expand.grid(carriers, dates)
names(date_carrier) <- c("carrier", "fl_date")Now we can merge the two dataframes using a left join.
%%R
flights_by_date_carrier <- merge(x = date_carrier, y = flights_by_date_carrier_1,
by.x = c("carrier", "fl_date"),
by.y = c("carrier", "fl_date"),
all.x = TRUE)Add a day of week column for convenience.
%%R
flights_by_date_carrier$weekday <- wday(flights_by_date_carrier$fl_date)Finally, compute the average number of flights.
%%R
flights_carrier_dow <- flights_by_date_carrier %>%
group_by(carrier, weekday) %>%
summarize(
avg_numflights = mean(numflights)
)Let’s plot it.
%%R
ggplot(data=flights_carrier_dow) + geom_bar(aes(x=factor(weekday, labels=c("Su","Mo","Tu","We","Th","Fr","Sa")), y=avg_numflights), stat = "identity") + facet_wrap(~carrier) +
xlab("Day of Week") +
ylab("Avg # of Flights") +
ggtitle("Avg # Flights by Day of Week and Carrier")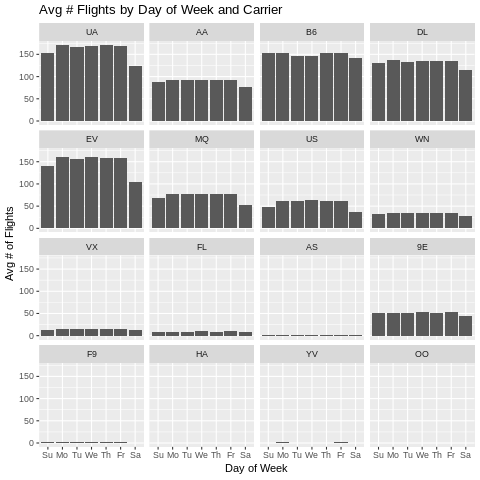
Closing remarks - check out hillmaker
In addition to simply counting number of bike rentals (or flights), we might be interested in related statistics such as the average and percentiles of the number of bikes in use by time of day and day of week. My hillmaker package is designed for just such analysis. You can find an example here of it being used to analyze the Pronto Cycle Share data.
Reuse
Citation
BibTeX citation:
@online{isken2018,
author = {Isken, Mark},
title = {Computing Daily Averages from Transaction Data Using Pandas
Can Be Tricky - {Part} 2},
date = {2018-07-18},
url = {https://bitsofanalytics.org/posts/daily-averages-cycleshare-part2/daily_averages_cycleshare_part2.html},
langid = {en}
}
For attribution, please cite this work as:
Isken, Mark. 2018. “Computing Daily Averages from Transaction Data
Using Pandas Can Be Tricky - Part 2.” July 18. https://bitsofanalytics.org/posts/daily-averages-cycleshare-part2/daily_averages_cycleshare_part2.html.