import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection._search import ParameterGrid
import seaborn as sns
import copyExcel “what if?” analysis with Python - Part 3: Simulation
Monte-Carlo simulation in Python
python
excel
simulation
In the first part of this series, I introduced the general idea of exploring using Python for typical spreadsheet modeling activities. We built both object-oriented (OO) and non-OO versions of a basic business model (the Bookstore Model - it’s repeated below for convenience) and learned a few things about doing OOP in Python. Then we designed and created a data_table function to do sensitivity analysis much like Excel’s Data Table tool (though our Python version can handle an arbitrary number of both input and output variables). In part 2 we created a goal_seek function that is reminiscent of Excel’s Goal Seek tool.
Now it’s time to add Monte-Carlo simulation capabilities to our little library of functions. We’ll stick with the same example. We are getting to the point where it would be convenient to package up our BookstoreModel class along with the data_table and goal_seek functions so that we could import them and use them here. I’ll hold off on that until the next installment. For now, I’ve just included the code. In the spirit of consistency with the first two posts, we’ll once again look at both OO and non-OO approaches to this problem.
You can also read and download the notebook based tutorial from GitHub.
%matplotlib inlineBookstore model
This example is based on one in the spreadsheet modeling textbook(s) I’ve used in my classes since 2001. I started out using Practical Management Science by Winston and Albright and switched to their Business Analytics: Data Analysis and Decision Making (Albright and Winston) around 2013ish. In both books, they introduce the “Walton Bookstore” problem in the chapter on Monte-Carlo simulation. Here’s the basic problem (with a few modifications):
- we have to place an order for a perishable product (e.g. a calendar),
- there’s a known unit cost for each one ordered,
- we have a known selling price,
- demand is uncertain but we can model it with some simple probability distribution,
- for each unsold item, we can get a partial refund of our unit cost,
- we need to select the order quantity for our one order for the year; orders can only be in multiples of 25.
A non-OO approach to Monte-Carlo simulation
Let’s start by repeating our basic non-OO model code for setting inputs and computing profit.
# Set all of our base input values except demand
unit_cost = 7.50
selling_price = 10.00
unit_refund = 2.50
order_quantity = 200def bookstore_profit(unit_cost, selling_price, unit_refund, order_quantity, demand):
'''
Compute profit in bookstore model
'''
order_cost = unit_cost * order_quantity
sales_revenue = np.minimum(order_quantity, demand) * selling_price
refund_revenue = np.maximum(0, order_quantity - demand) * unit_refund
profit = sales_revenue + refund_revenue - order_cost
return profitGenerating random demand values
Assume we’ve used historical data to estimate the mean and standard deviation of demand. Furthermore, let’s pretend that a histogram revealed a relatively normal looking distribution.
# Demand parameters
demand_mean = 193
demand_sd = 40We can generate a vector of random demand realizations and then feed that vector to our compute_profit function. The result will be a vector of profits with the same number of elements as in our demand vector. Then we can analyze the results using descriptive statistics and plotting.
Recently, numpy has updated their random variable generation routines. The details are at https://numpy.org/doc/stable/reference/random/index.html.
The scipy.stats module contains a large number of probability distributions and each has numerous functions for calculating things such as pdf or CDF values, quantiles, and various moments. You can see the details at https://docs.scipy.org/doc/scipy/reference/stats.html.
Let’s assume we want to model demand with a normal distribution. We already initialized variables demand_mean and demand_sd with the mean and standard deviation of demand.
The plan:
- import random number generation function from numpy,
- initialize a random number generator object,
- use numpy’s
normalfunction to generate normally distributed random variates (we’ll do 1000), - compute basic summary stats for the generated random variates,
- create a histogram of the generated random variates to make sure they look normal (they will),
- use
scipy.stats.normto create a normal distribution object, - use that normal distribution object to overlay a normal density curve on our histogram.
print(f"Demand mean = {demand_mean}")
print(f"Demand sd = {demand_sd}")Demand mean = 193
Demand sd = 40Before we launch into this, let’s consider something that modelers often do with uncertain quantities - they simply replace them with their mean. As a benchmark, let’s see what we’d estimate profit to be if we simply used the value of demand_mean. Remember this number.
deterministic_profit = bookstore_profit(unit_cost, selling_price, unit_refund, order_quantity, demand_mean)
deterministic_profit447.5First we need to import the default random number generator and create a random generator variable. I’ll use 4470 as the seed. This generator generates numbers uniformly between 0 and 1, which can be used to generate random variates from whatever distribution we choose.
from numpy.random import default_rng
rg = default_rng(4470)
rg.random() # Generate one just to see it work0.45855804438027437Generate 1000 random variates from a normal distribution with our given mean and standard deviation.
demand_sim = rg.normal(demand_mean, demand_sd, 1000)Obviously we are generating variates from a continuous distribution.
demand_sim[:10]array([217.03616307, 133.37168121, 231.54405167, 215.05711803,
183.66669223, 268.28497816, 255.99191635, 188.58125604,
164.62174798, 170.1384389 ])If we want integer valued demands, we can simply round the values.
demand_sim = np.around(rg.normal(demand_mean, demand_sd, 1000))
demand_sim[:10]array([218., 203., 186., 203., 215., 151., 255., 176., 223., 252.])Before plotting the histogram, let’s compute basic summary stats for our vector of random demands.
print(f"Mean demand = {demand_sim.mean():.3f}, Std dev demand = {demand_sim.std():.3f}")Mean demand = 192.056, Std dev demand = 40.170Now use SciPy to create a normal random variable instance with the mean and standard deviation based on demand_mean and demand_sd. Note the data type. Then we’ll be able to use its built in pdf method to plot its density and its ppf method to get percentiles to use for our x-axis limits.
from scipy.stats import normrv_normal = norm(loc=demand_mean, scale=demand_sd)
print(type(rv_normal))<class 'scipy.stats._distn_infrastructure.rv_frozen'>plt.title("Demand histogram")
plt.xlabel("Demand")
plt.ylabel("Density")
plt.hist(demand_sim, density=True);
x_normal = np.linspace(rv_normal.ppf(0.0001),
rv_normal.ppf(0.999), 500)
plt.plot(x_normal, rv_normal.pdf(x_normal),
'r-', lw=3, alpha=0.6, label='Normal pdf');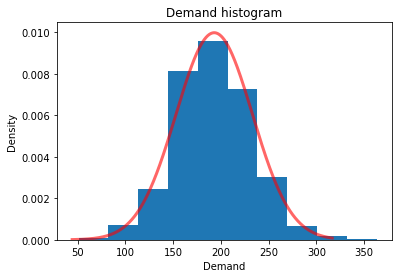
Running the simulation
Now that we can generate random demands, we can simulate by simply passing in the vector of random demands to the compute_profit function - all the other model inputs are held fixed at their current values. Let’s remind ourselves of these values.
message = f"unit_cost: {unit_cost} \n" \
f"selling_price: {selling_price} \n" \
f"unit_refund: {unit_refund} \n" \
f"order_quantity: {order_quantity}"
print(message)unit_cost: 7.5
selling_price: 10.0
unit_refund: 2.5
order_quantity: 200We use a list comprehension to evaluate profit for each demand realization. This is exactly the same way we did the non-OO 1-way data table in the first part of this series. Let’s wrap the resulting list with the pandas Series constructor so that we can use some of pandas built in analysis tools such as the describe method.
profit_sim = pd.Series([(bookstore_profit(unit_cost, selling_price, unit_refund, order_quantity, d))
for d in demand_sim])Analyzing the simulation results
profit_sim.describe()count 1000.000000
mean 347.832500
std 190.630397
min -617.500000
25% 243.125000
50% 432.500000
75% 500.000000
max 500.000000
dtype: float64The Flaw of Averages shows up here (compare mean of simulation output to the profit we got by replacing demand with mean demand).
print(f"Deterministic profit = {deterministic_profit}")
print(f"Simulation profit = {profit_sim.describe()['mean']}")Deterministic profit = 447.5
Simulation profit = 347.8325By ignoring uncertainty, we were wildly optimistic as to what our mean profit would be.
QUESTION Why do you think these numbers are so different?
Let’s look at the histogram of profit based on the simulation model to shed some light on this.
plt.title("Profit histogram")
plt.xlabel("Profit")
plt.ylabel("Num observations")
plt.ylim(0, 600)
plt.hist(profit_sim, density=False);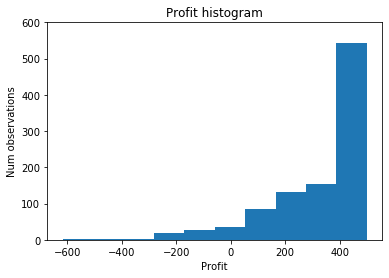
While demand was normally distributed, the resulting profit distribution is definitely not normally distributed. I’m sure you’ve figured out why this histogram has the shape it does and how this relates to the Flaw of Averages.
The scipy.stats library can be used to answer typical questions about the distribution of profit.
from scipy import statsWhat’s the chance we have a negative profit?
print(stats.percentileofscore(profit_sim, 0) / 100.0)0.063# Probability profit is between -200, 200
print((stats.percentileofscore(profit_sim, 200) - stats.percentileofscore(profit_sim, -200)) / 100.0)0.1895We can create an empirical cumulative distribution function for profit_sim and then use it to customize plots.
profit_cdf = stats.cumfreq(profit_sim)x = profit_cdf.lowerlimit + np.linspace(0, profit_cdf.binsize * profit_cdf.cumcount.size,
profit_cdf.cumcount.size)fig = plt.figure(figsize=(10, 4))
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
ax1.hist(profit_sim, bins=25)
ax1.set_title('Histogram of simulated profit')
ax1.set_xlabel('Profit')
ax2.bar(x, profit_cdf.cumcount, width=profit_cdf.binsize)
ax2.set_title('Cumulative histogram of simulated profit')
ax2.set_xlabel('Profit')
ax2.set_xlim([x.min(), x.max()])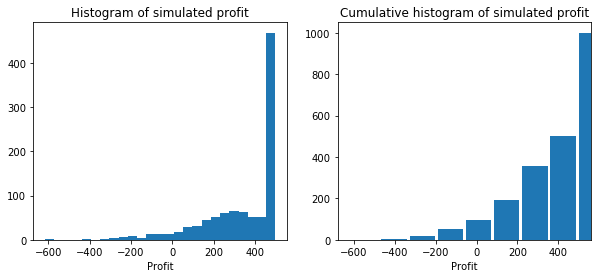
Multiple Uncertain Inputs
Again, note how we used a list comprehension to evaluate profit for each demand realization. If we have multiple random inputs we cannot use multiple for statements as we don’t want the cross product of the random number vectors. Instead we’d need to zip them up into tuples. Here’s a simple example of tuple zipping.
alpha = [1, 2, 3]
beta = [10, 20, 30]
for t in zip(alpha, beta):
print(t)(1, 10)
(2, 20)
(3, 30)Assume we have some uncertainty around both the unit_cost and unit_refund values. Let’s model our uncertainty with uniform distributions:
unit_cost\(\sim U(7.00, 8.00)\)unit_refund\(\sim U(2.00, 3.00)\)
unit_cost_sim = rg.uniform(7.0, 8.0, 1000)
unit_refund_sim = rg.uniform(2.0, 3.0, 1000)
rv_uniform = stats.uniform(loc=7.0, scale=1.0)plt.title("Unit Cost histogram")
plt.xlabel("Unit Cost")
plt.ylabel("Density")
plt.hist(unit_cost_sim, density=True);
x_uniform = np.linspace(7.0, 8.0, 100)
plt.plot(x_uniform, rv_uniform.pdf(x_uniform),
'r-', lw=3, alpha=0.6, label='Uniform pdf');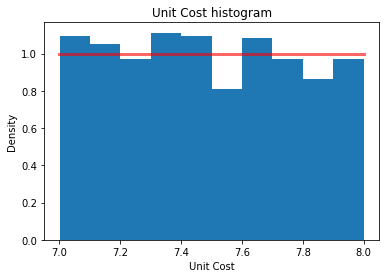
Let’s zip the three random vectors into tuples.
random_inputs = zip(demand_sim, unit_cost_sim, unit_refund_sim)profit_sim_2 = pd.Series([(bookstore_profit(uc, selling_price, uf, order_quantity, d))
for (d, uc, uf) in random_inputs])plt.title("Profit histogram for three uncertain inputs")
plt.xlabel("Profit")
plt.ylabel("Num observations")
plt.ylim(0, 600)
plt.hist(profit_sim_2, density=False);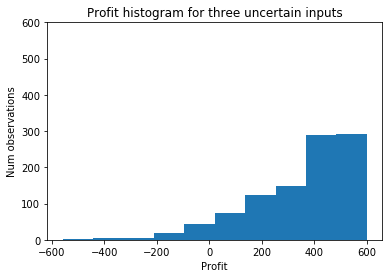
The additional uncertainty has made the distribution somewhat less extreme in the right tail (it’s still highly skewed).
Multiple scenarios: profit vs order quantity
In addition to random inputs, we often have other inputs we want to vary over a defined range - i.e. scenarios. Just as we did Part 1 of this series with data tables, we can use a list comprehension to iterate over the scenarios.
# Create array of order quantities (the scenarios)
order_quantity_range = np.arange(100, 400, 25)
# Create simulation data table
sim_table_1 = [(oq, bookstore_profit(unit_cost, selling_price, unit_refund, oq, d))
for oq in order_quantity_range for d in demand_sim]
# Convert to dataframe
stbl_1_df = pd.DataFrame(sim_table_1, columns=['OrderQuantity', 'Profit'])
# Plot the results
profit_histo_g = sns.FacetGrid(stbl_1_df, col="OrderQuantity", sharey=True, col_wrap=3)
profit_histo_g = profit_histo_g.map(plt.hist, "Profit")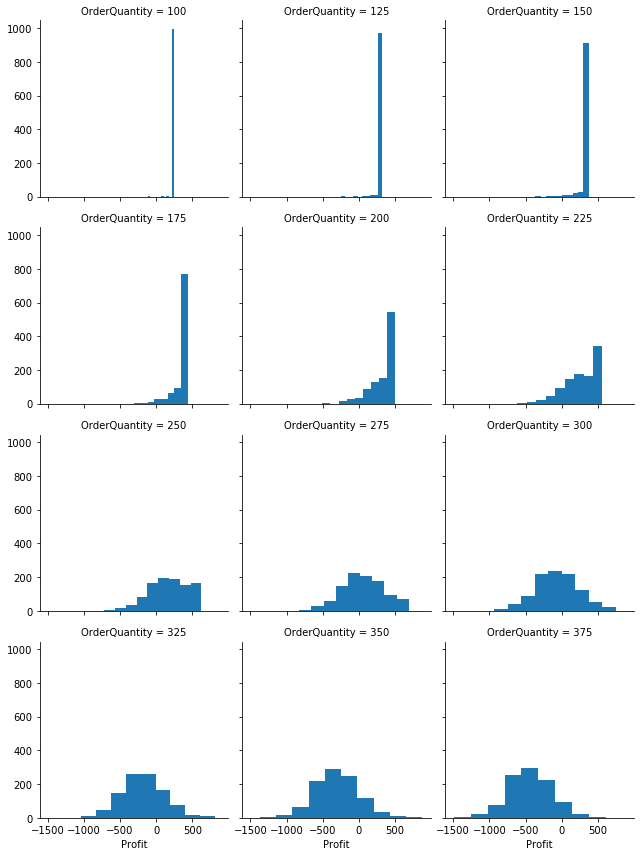
Another way to compare the profit distributions across order quantities is to use boxplots.
profit_box_g = sns.boxplot(x="OrderQuantity", y="Profit", data=stbl_1_df)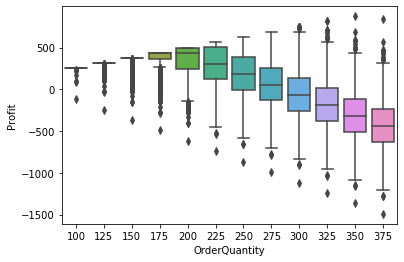
Repeat simulation using OO approach
Just as we leveraged our non-OO data table approach for simulation, let’s do the same for the OO version. We should be able to use scikit-learn’s ParameterGrid function for optional scenario generation (think RiskSimTable if you’ve used @Risk). We don’t want to use ParameterGrid for the random inputs as we don’t want all combinations of them - we just want to evaluate one replication per row. We’ll use the same random vectors that we created above. The basic initial design of our simulate function will be based on the following:
- The first argument will be a model object (i.e. something like the
BookstoreModelmodel) that contains anupdatemethod. Soon, we should add an abstractModelclass from which specific models such as theBookstoreModelclass can be created. The abstract class will contain theupdatemethod. - The random inputs will be passed in as a dictionary whose keys are the input variables being modeled as random and who values are an iterable representing the draws from some probability distribution. Structurally, this is similar to how inputs are specified in the
data_tablefunction. - We can optionally pass in a dictionary of scenario inputs. This is exactly like the
data_tablevariable input.- If no scenario input dictionary is passed in, a single simulation scenario is run using the current input values in the model object,
- If a scenario input dictionary is passed in, then a simulation scenario is run for every combination of parameters in the dictionary. Again, this is just like we do in the
data_tablefunction.
- The output will be a set of dictionaries containing dataframes of simulation output as well standard summary stats and plots.
In Parts 1 and 2 of this series we created the BookstoreModel class as well as data_table and goal_seek functions. Instead of repeating those definitions here, I’ve moved their code into whatif.py and we can just import it.
from whatif import BookstoreModelLet’s reset our base input values and then create a new BookstoreModel object with these property values.
unit_cost = 7.50
selling_price = 10.00
unit_refund = 2.50
order_quantity = 200
demand_mean = 193
demand_sd = 40
demand = demand_meanmodel2 = BookstoreModel(unit_cost=unit_cost,
selling_price=selling_price,
unit_refund=unit_refund,
order_quantity=order_quantity,
demand=demand)Again, we will model three of our inputs, demand, unit_cost, and unit_refund as random variables. All three were creatd earlier in the notebook, but here they are again. Let’s just do 100 scenarios to reduce the number of output rows for viewing.
num_reps = 100
demand_sim = rg.normal(demand_mean, demand_sd, num_reps)
unit_cost_sim = rg.uniform(7.0, 8.0, num_reps)
unit_refund_sim = rg.uniform(2.0, 3.0, num_reps)
random_inputs = {'demand': demand_sim,
'unit_cost': unit_cost_sim,
'unit_refund': unit_refund_sim}It’s also perfectly fine to not pre-generate the random variates. If we decide to specify the inputs in this way (next cell), then our simulate function should include a boolean input that specifies whether the raw simulated input values should be saved and returned as part of its output.
random_inputs = {'demand': rg.normal(demand_mean, demand_sd, num_reps),
'unit_cost': rg.uniform(7.0, 8.0, num_reps),
'unit_refund': rg.uniform(2.0, 3.0, num_reps)}For the scenario inputs, we’ll use the range of order quantity values used in the data_table examples.
scenario_inputs = {'order_quantity': np.arange(70, 321, 50)}
list(ParameterGrid(scenario_inputs))[{'order_quantity': 70},
{'order_quantity': 120},
{'order_quantity': 170},
{'order_quantity': 220},
{'order_quantity': 270},
{'order_quantity': 320}]We’ll stick with profit as the only output variable for now.
sim_outputs = ['profit']Here’s my first version of a simulate function.
def simulate(model, random_inputs, outputs, scenario_inputs=None, keep_random_inputs=False):
'''Simulate model for one or more scenarios
Parameters
----------
model : object
User defined object containing the appropriate methods and properties for computing outputs from inputs
random_intputs : dict of str to sequence of random variates
Keys are stochastic input variable names and values are sequence of $n$ random variates, where $n$ is the number of simulation replications
outputs : list of str
List of output variable names
scenario_inputs : optional (default is None), dict of str to sequence
Keys are deterministic input variable names and values are sequence of values for each scenario for this variable. Is consumed by
scikit-learn ParameterGrid() function. See https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.ParameterGrid.html
keep_random_inputs : optional (default is False), boolean
If True, all the random input variates are included in the results dataframe
Returns
-------
results_df : pandas DataFrame
Values of all outputs for each simulation replication. If `scenario_inputs` is not None, then this is also for every combination of scenario inputs
'''
# Clone the model
model_clone = copy.deepcopy(model)
# Update clone with random_inputs
model_clone.update(random_inputs)
# Store raw simulation input values if desired
if keep_random_inputs:
scenario_base_vals = vars(model_clone)
else:
scenario_base_vals = vars(model)
# Initialize output counters and containers
scenario_num = 0
scenario_results = []
# Check if multiple scenarios
if scenario_inputs is not None:
# Create parameter grid for scenario inputs
sim_param_grid = list(ParameterGrid(scenario_inputs))
# Scenario loop
for params in sim_param_grid:
model_clone.update(params)
# Initialize scenario related outputs
result = {}
scenario_vals = copy.copy(params)
result['scenario_base_vals'] = scenario_base_vals
result['scenario_num'] = scenario_num
result['scenario_vals'] = scenario_vals
raw_output = {}
# Output measure loop
for output_name in outputs:
output_array = getattr(model_clone, output_name)()
raw_output[output_name] = output_array
# Gather results for this scenario
result['output'] = raw_output
scenario_results.append(result)
scenario_num += 1
return scenario_results
else:
# Similar logic to above, but only a single scenario
results = []
result = {}
result['scenario_base_vals'] = scenario_base_vals
result['scenario_num'] = scenario_num
result['scenario_vals'] = {}
raw_output = {}
for output_name in outputs:
output_array = getattr(model_clone, output_name)()
raw_output[output_name] = output_array
result['output'] = raw_output
results.append(result)
return resultsLet’s run the simulation.
model2_results = simulate(model2, random_inputs, sim_outputs, scenario_inputs)The output (for now) is a list of dictionaries. Each dictionary corresponds to one scenario (in this case, one value of order_quantity. Let’s pluck out one scenario near the middle of the order quantity values and explore the outputs.
which_scenario = 4
# What are the keys in the output dictionaries
model2_results[which_scenario].keys()dict_keys(['scenario_base_vals', 'scenario_num', 'scenario_vals', 'output'])model2_results[which_scenario]['scenario_vals']{'order_quantity': 270}for scenario in model2_results:
print(scenario['scenario_num'], scenario['scenario_vals'], scenario['output']['profit'].mean())0 {'order_quantity': 70} 176.0191921065434
1 {'order_quantity': 120} 299.6121899248544
2 {'order_quantity': 170} 381.3838755407154
3 {'order_quantity': 220} 287.56197705166164
4 {'order_quantity': 270} 17.00942728215051
5 {'order_quantity': 320} -306.2002083301332Let’s take a look at an entry from one of the scenario dictionaries.
model2_results[which_scenario]{'scenario_base_vals': {'unit_cost': 7.5,
'selling_price': 10.0,
'unit_refund': 2.5,
'order_quantity': 200,
'demand': 193},
'scenario_num': 4,
'scenario_vals': {'order_quantity': 270},
'output': {'profit': array([ 94.07848039, 10.29745358, 235.96489009, -436.72652984,
-226.9675955 , 601.45820208, 293.64935644, -425.72328478,
-390.00020874, -15.59715502, 306.2150294 , -329.35451825,
661.32783105, -36.51672742, 230.13464279, -323.27742095,
505.40223752, 337.80405457, -119.90157877, 132.33787233,
-901.24678476, 390.99625756, -255.71597319, 461.87713384,
-313.95088686, 210.3540985 , 366.73915719, 243.41026106,
646.59828596, -137.23342344, -171.73200896, 181.77906894,
142.5739788 , 114.81682308, 28.4746822 , 45.60270247,
-438.76329113, -212.90798302, -34.84212884, -29.78550324,
265.03280914, 220.44086959, -224.92077887, -559.73996413,
684.40416776, 519.65848137, 483.70855004, -502.66943395,
-157.95695122, 581.86172322, 21.63677824, 34.13716094,
-189.3820352 , -21.7908457 , 64.30107072, -754.19756385,
142.77595237, 395.56677694, -350.41850917, -426.46940612,
118.88087006, 214.55339188, -92.55406086, 121.01250136,
-82.47241949, -254.37175642, -292.10614549, 369.40002614,
258.36381197, 70.47743792, 191.73247923, -142.21122732,
-362.21145521, 438.48568471, 507.46163446, 133.84719243,
-232.25685544, 388.80888517, 228.887753 , -309.37641263,
177.4884349 , 180.43407225, -359.01194377, 482.4031242 ,
-242.64898564, 580.1099699 , -236.14094472, -421.32776301,
-252.41477677, 762.57930743, -293.51728502, -559.60535181,
-251.50967301, -38.58166773, -370.77754468, -383.69639033,
42.64023432, 195.50770653, -309.42618891, 56.45870938])}}Let’s write a gather results function to turn results object into analysis ready DataFrame.
def get_sim_results_df(results):
dfs = []
for r in results:
df = pd.DataFrame(r['output'])
df['scenario_num'] = r['scenario_num']
for key, val in r['scenario_vals'].items():
df[key] = val
dfs.append(df)
results_df = pd.concat(dfs)
return results_dfmodel2_results_df = get_sim_results_df(model2_results)model2_results_df| profit | scenario_num | order_quantity | |
|---|---|---|---|
| 0 | 170.275117 | 0 | 70 |
| 1 | 164.192202 | 0 | 70 |
| 2 | 167.876925 | 0 | 70 |
| 3 | 160.018106 | 0 | 70 |
| 4 | 181.568184 | 0 | 70 |
| ... | ... | ... | ... |
| 95 | -732.460739 | 5 | 320 |
| 96 | -306.229201 | 5 | 320 |
| 97 | -106.301086 | 5 | 320 |
| 98 | -644.780031 | 5 | 320 |
| 99 | -246.836081 | 5 | 320 |
600 rows × 3 columns
Now it’s easy to do plots like the following:
sns.boxplot(x="order_quantity", y="profit", data=model2_results_df);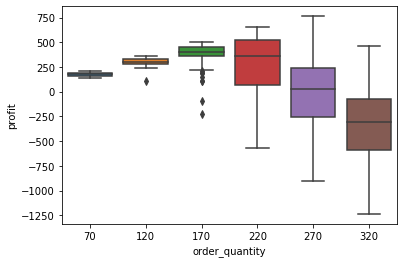
… or this:
profit_histo_g2 = sns.FacetGrid(model2_results_df, col='order_quantity', sharey=True, col_wrap=3)
profit_histo_g2 = profit_histo_g2.map(plt.hist, "profit")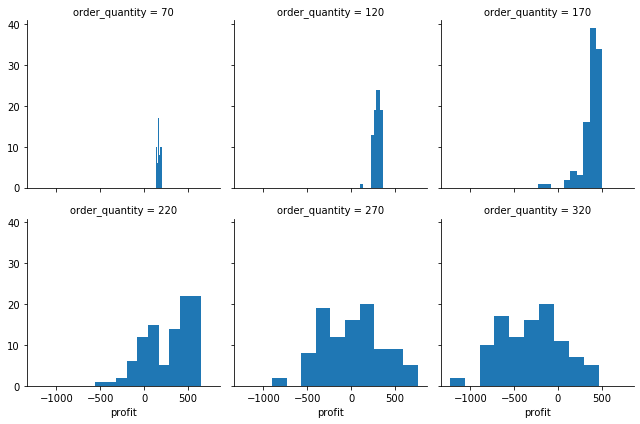
… and statistical summaries like this:
model2_results_df.groupby(['scenario_num'])['profit'].describe()| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| scenario_num | ||||||||
| 0 | 100.0 | 176.019192 | 19.141648 | 141.097517 | 162.634144 | 174.243792 | 191.941489 | 209.399164 |
| 1 | 100.0 | 299.612190 | 38.534079 | 106.971360 | 278.066820 | 298.703644 | 329.042553 | 358.969995 |
| 2 | 100.0 | 381.383876 | 115.621643 | -229.101355 | 357.531065 | 406.647547 | 456.672025 | 506.665625 |
| 3 | 100.0 | 287.561977 | 272.662324 | -565.174070 | 69.842998 | 358.567460 | 526.428417 | 654.114823 |
| 4 | 100.0 | 17.009427 | 345.595096 | -901.246785 | -252.904022 | 31.305922 | 237.826233 | 762.579307 |
| 5 | 100.0 | -306.200208 | 351.137452 | -1237.319500 | -585.551638 | -302.533435 | -71.989753 | 465.705377 |
Lot’s more to do, but let’s stop here for this post. The basic design seems ok and we can build on this in future installments.
Wrap up and next steps
We have added a basic simulate function to our data_table and goal_seek functions. Python is proving to be quite nice for doing Excel-style “what if?” analysis.
In Part 4 of this series, we’ll make some improvements and do some clean-up on our classes and functions. We’ll move everything into a single whatif.py module and learn how to create a Python package to make it easy to use and share our new functions. We’ll try out our package on a new model and sketch out some ideas for future enhancements to the package. It’s important we also start creating some basic documentation and a user guide.
Reuse
Citation
BibTeX citation:
@online{isken2021,
author = {Isken, Mark},
title = {Excel “What If?” Analysis with {Python} - {Part} 3:
{Simulation}},
date = {2021-02-21},
url = {https://bitsofanalytics.org/posts/what-if-3-simulation/what_if_3_simulation.html},
langid = {en}
}
For attribution, please cite this work as:
Isken, Mark. 2021. “Excel ‘What If?’ Analysis with
Python - Part 3: Simulation.” February 21. https://bitsofanalytics.org/posts/what-if-3-simulation/what_if_3_simulation.html.