Today I got an email from DataCamp inviting me to try out their new AI Assistant (powered by OpenAI) within their cloud based notebook environment called Workspace. I teach analytics courses in a business school. For one of those courses, students get access to DataCamp for the semester but its use in the course is entirely optional. They have some very nice tutorials for those getting started in analytics and data science and it gives students another way to start to learn to do analytics work R and Python.
The AI Assistant invite was not expected and I really hadn’t even thought about DataCamp rolling out something like this - but it makes perfect sense. So, I figured I might as well give it a try. Now, I’ve been (trying) keeping up with the LLM/GPT/AI frenzy that’s been happening since last fall, but other than a few basic interactions with ChatGPT3.5, I really haven’t used them much at all. As an educator, I have been closely following discussions in the higher ed community about the impact of these tools. I say all that to emphasize that I’m very much a GPT newb and what follows is by no means a rigorous or exhaustive look at this AI Assistant. I’m sure there are better ways to interact with this thing. This is just me messing around with some typical kinds of things I teach and use in my classes.
Basic (and not so basic) analysis of cycle share data
Within the Workspace cloud notebook environment, there are a bunch of preloaded datasets including some cycle share data that has already been summarized in terms of number rides per date and includes some weather related variables. I did some basic pandas group by queries and simple plots and the AI Assistant worked quite well. In my classes I’ve used cycle share data but we typically work with the raw trip data in which each row is a bike rental instance. I noticed that you can upload your own dataset into a Workspace. Ok, let’s see what this thing can do with a dataset that is not pre-loaded, but is very prominent out on the interwebs.
I uploaded the trip.csv datafile from the Pronto Cycleshare Dataset. It’s a few hundred thousand rows and just under 50Mb in size. No problem with the upload.
Since I knew we were going to be doing some datetime work, I helped the AI with the import by asking:
Import the trip.csv file into a pandas dataframe. The starttime and stoptime fields are datetimes.
It generated the following perfectly correct code.
::: {#7e412f85-8b0c-4992-83bf-30179bd4cca3 .cell executionTime=‘24868’ lastSuccessfullyExecutedCode=’import pandas as pd
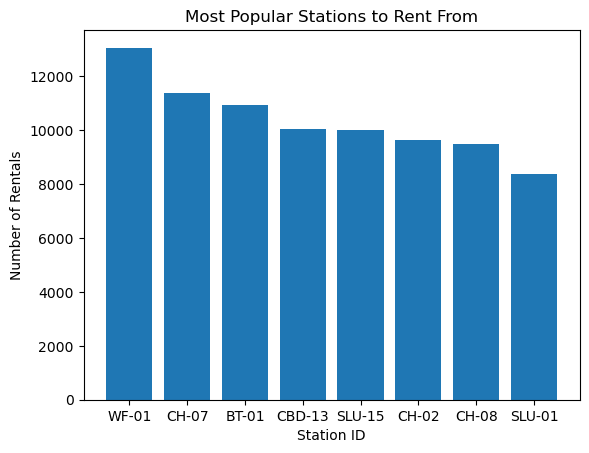
Let’s find the 8 most popular stations to rent from.
List the 8 most popular stations from which to rent a bike.
The generated code contains a column name that doesn’t exist in the dataframe. No doubt, there’s another cycle share dataset out there that does use this column name.
popular_stations = df['start station name'].value_counts().head(8)print(popular_stations)
When I clicked Fix Error, I got:
The error is caused by the key ‘start station name’ not being present in the DataFrame ‘df’. This could be due to a misspelling or the key not existing in the DataFrame. To fix the error, we can check the column names in the DataFrame and use the correct key. Here’s the corrected code:
plt.bar(popular_stations.index, popular_stations.values) plt.title('Most Popular Stations to Rent From') plt.xlabel('Station ID') plt.ylabel('Number of Rentals') plt.show()’ execution_count=18}
import matplotlib.pyplot as pltpopular_stations = df['from_station_id'].value_counts().head(8)plt.bar(popular_stations.index, popular_stations.values)plt.title('Most Popular Stations to Rent From')plt.xlabel('Station ID')plt.ylabel('Number of Rentals')plt.show()
:::
In another attempt at doing the same thing, the AI Assistant used the correct column name from the previous code chunk. Strangely, it then recomputed popular_stations instead of just using it.
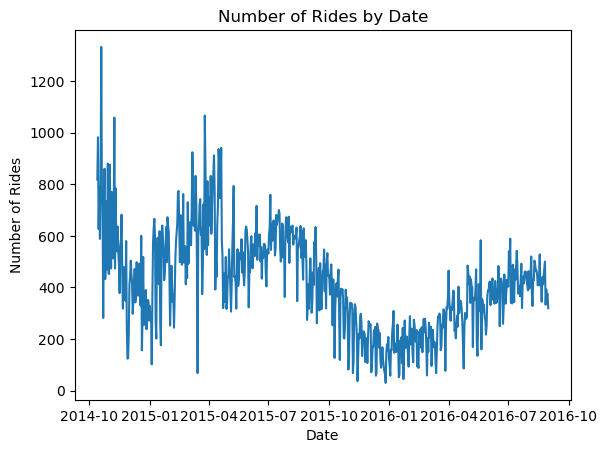
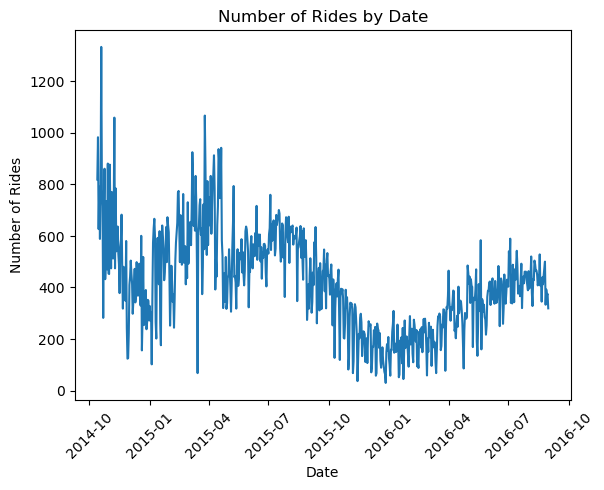
Now let’s make a line chart of the number of rides by date.
make a line chart of the number of rides by date.
It used a non-existent column for the start date even though we told it that starttime and stoptime were dates. Not surprisingly, the Fix Error identified the bad column name but didn’t go further than that in terms of suggesting possible columns to use (i.e. the ones whose datatype is date). So, here’s the manually fixed up code:
::: {#687e1546-b58f-42e1-b6c4-4c5ba5ccd7cf .cell executionTime=‘347’ lastSuccessfullyExecutedCode=’import matplotlib.pyplot as plt
group the data by date and count the number of rides
plt.plot(rides_by_date.index, rides_by_date.values) plt.title('Number of Rides by Date') plt.xlabel('Date') plt.ylabel('Number of Rides') plt.show()’ execution_count=19}
import matplotlib.pyplot as plt# group the data by date and count the number of ridesrides_by_date = df.groupby(df['starttime'].dt.date).size()# plot the line chartplt.plot(rides_by_date.index, rides_by_date.values)plt.title('Number of Rides by Date')plt.xlabel('Date')plt.ylabel('Number of Rides')plt.show()
:::
I asked it to make the x-axis more readable and it produced the following bit of correct code with rotated axis labels.
::: {#ba1e92c9-fca8-4429-9420-a7e1918cc5bd .cell executionTime=‘416’ lastSuccessfullyExecutedCode=’import matplotlib.pyplot as plt
group the data by date and count the number of rides
plt.plot(rides_by_date.index, rides_by_date.values) plt.title('Number of Rides by Date') plt.xlabel('Date') plt.ylabel('Number of Rides')
rotate the x-axis labels for readability
plt.xticks(rotation=45)
plt.show()’ execution_count=20}
import matplotlib.pyplot as plt# group the data by date and count the number of ridesrides_by_date = df.groupby(df['starttime'].dt.date).size()# plot the line chartplt.plot(rides_by_date.index, rides_by_date.values)plt.title('Number of Rides by Date')plt.xlabel('Date')plt.ylabel('Number of Rides')# rotate the x-axis labels for readabilityplt.xticks(rotation=45)plt.show()
:::
Strangely, I tried to reproduce the above behavior but the generated code went back to using non-existent column names and instead of rotating the text it used DateFormatter objects. Also, the generated code would do things like trying to convert columns to datetimes even if they were already datetimes.
And now for something more difficult
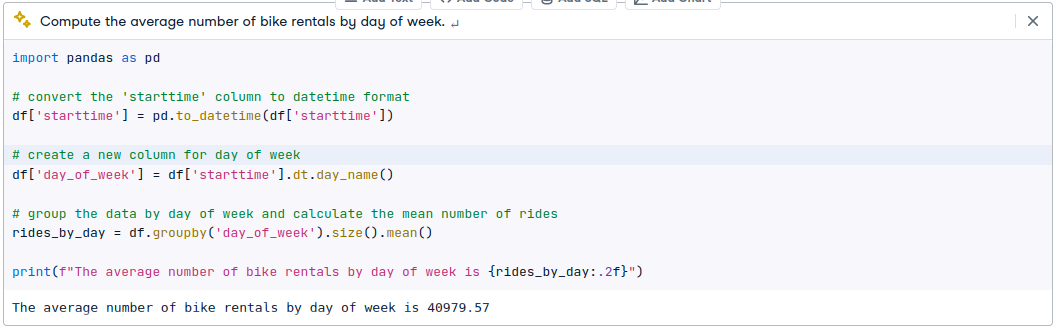
Ok, let’s try something tougher like computing the average number of riders by day of week. This is not particularly easy since you have to worry about things like the specific date range used (could have a different number of, say, Mondays than the other days of the week) and the possibility of there being zero rides within a given group. Now, the zero thing is a non-issue for overall average number of rides by day of week, but, if we do something like computing the average number of rides by starting station by day of week and hour of day, there most certainly will be instances of zero rides in some of those groups. If they aren’t properly accounted for, the averages will be inflated. I did a blog post on this issue several years ago (so, there’s a chance it’s in the training data for the LLM).
Compute the average number of bike rentals by day of week.
Here’s what I got for one of the attempts:
Another time I tried the same query I got the following code. Well, actually it wanted to read some completely different csv file but I manually fixed it. Nevertheless, the computation is wrong (really wrong). If you look back at the line plot, you’ll see that there are around 400-500 rides per day.
::: {#2af85480-2de1-4252-b332-73d227aaf991 .cell executionTime=‘12792’ lastSuccessfullyExecutedCode=’import pandas as pd
load the data
df = pd.read_csv('trip.csv')
convert starttime column to datetime datatype
df['starttime'] = pd.to_datetime(df['starttime'])
create a new column for day of week
df['day_of_week'] = df['starttime'].dt.day_name()
group the data by day of week and calculate the average number of rides
#import pandas as pd# load the data#df = pd.read_csv('trip.csv')# convert starttime column to datetime datatypedf['starttime'] = pd.to_datetime(df['starttime'])# create a new column for day of weekdf['day_of_week'] = df['starttime'].dt.day_name()# group the data by day of week and calculate the average number of ridesavg_rides_by_day = df.groupby('day_of_week')['tripduration'].count() / df['day_of_week'].nunique()
Yeah, that’s not even close to being right. The AI Assistant also likes to repeat import statements and reread files. This makes it difficult to create a coherent workflow as it’s easy to inadvertantly clobber previous data prep code or you have to remember to comment out unneeded file rereads.
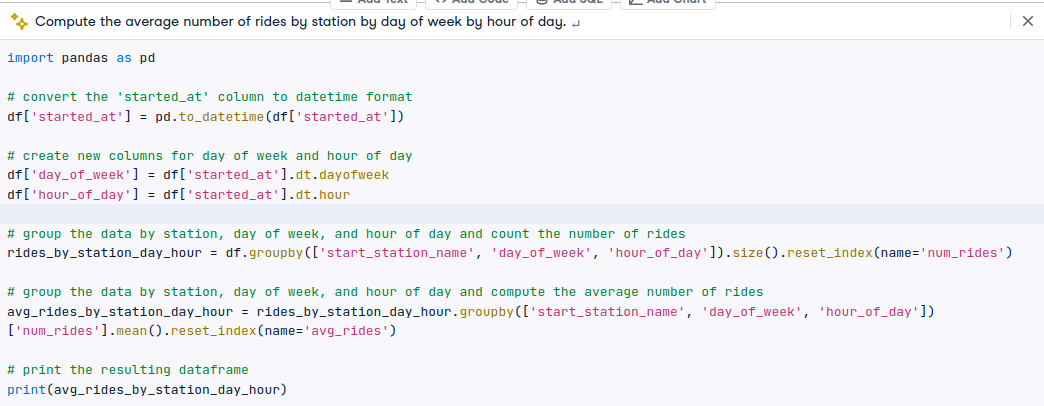
I also tried asking for code to do average number of rides by station by day of week by hour of day. Again, got bad fields and incorrect computations. There are definitely groups with zero rides and this code isn’t taking that into account.
That’s enough for now.
Parting thoughts
I certainly wasn’t surprised that the AI Assistant failed miserably on this last task as it’s not a simple query and the correct approach is unlikely to be very prominent in the training data. I was a bit surprised how often the AI Assistant would use non-existent column names or filenames, or try to do datatype conversions on columns that were already of the desired data type. It is certainly capable of creating boilerplate code for simple things which can then be manually patched up (e.g. fixing column names). I’m sure it will improve over time via some sort of reinforcement learning or non-LLM based tweaks to prevent things like nonexistent column name use. For now, I’m sticking with StackOverflow and writing my own code.
 :::
::: :::
::: :::
:::